¶ 需要补充的一些命令
¶ free - 查看内存使用情况
查看内存和交换分区(虚拟内存)的情况。
ding@ding-server:~$ free
total used free shared buff/cache available
Mem: 16393508 10449532 1751160 84464 4192816 5560148
Swap: 4194300 94208 4100092
选项:
-b/-k/-m/-g:以对应单位显示(默认为-k,即 KiB)-s 秒数:每隔一段时间执行一次-h:以可读形式显示
列:
- 总共装配内存
- 使用的内存
- 未使用的内存
- 被
tmpfs使用的内存 - 缓冲区 / 缓存
- 可用内存
¶ last - 查看登录记录
ding@ding-server:~$ last
foxconn pts/0 10.94.5.157 Thu May 26 16:22 still logged in
foxconn pts/0 10.94.5.188 Thu May 26 15:10 - 15:17 (00:07)
reboot system boot 5.4.0-110-generi Mon May 23 13:59 still running
reboot system boot 5.4.0-110-generi Thu May 12 15:50 - 13:58 (10+22:08)
...
foxconn tty1 Fri Apr 1 18:08 - down (00:04)
reboot system boot 5.4.0-107-generi Fri Apr 1 18:07 - 18:12 (00:05)
wtmp begins Fri Apr 1 18:07:21 2022
不包括切换用户。
选项:
-f 文件:指定记录文件-n 整数:指定输出记录数-w:显示完整用户名。否则,如果用户名超过 8 个字,超出部分会被隐去
默认查找的文件为 /var/log/wtmp。
/var/log/btmp 记录了最近尝试登录但未登录成功的记录,可以查看是否遭受攻击。
ding@ding-server:~$ sudo last -f /var/log/btmp
oracle ssh:notty 223.113.52.38 Sun May 15 16:52 - 18:34 (01:41)
test ssh:notty 60.171.76.133 Sat May 14 13:22 - 16:52 (1+03:29)
hadoop ssh:notty 223.113.52.38 Fri May 13 18:44 - 13:22 (18:38)
es ssh:notty 221.215.21.91 Wed May 11 18:54 - 18:44 (1+23:49)
user ssh:notty 196.1.219.9 Wed May 11 01:28 - 18:54 (17:26)
git ssh:notty 60.171.76.133 Mon May 9 08:54 - 01:28 (1+16:34)
postgres ssh:notty 60.171.76.133 Mon May 9 08:40 - 08:54 (00:14)
jiang ssh:notty 162.14.129.194 Sun May 8 12:04 - 15:24 (03:19)
dash ssh:notty 162.14.129.194 Sun May 8 10:09 - 12:04 (01:54)
grid ssh:notty 162.14.129.194 Sun May 8 07:46 - 10:09 (02:23)
tomcat ssh:notty 162.14.129.194 Sun May 8 00:36 - 07:46 (07:09)
elastics ssh:notty 162.14.129.194 Thu May 5 11:27 - 15:45 (04:18)
bot ssh:notty 162.14.129.194 Thu May 5 06:40 - 11:27 (04:46)
app ssh:notty 162.14.129.194 Thu May 5 00:56 - 06:40 (05:43)
jack ssh:notty 162.14.129.194 Wed May 4 16:21 - 00:56 (08:35)
push ssh:notty 162.14.129.194 Wed May 4 11:05 - 13:29 (02:23)
db2inst1 ssh:notty 162.14.129.194 Wed May 4 10:08 - 11:05 (00:57)
...
登录相关的文件为二进制数据文件,无法用文本方式查看。
file命令可以查看文件类型。ding@ding-server:~$ file /var/log/wtmp /var/log/wtmp: dBase III DBT, version number 0, next free block index 2
¶ lastlog - 每个用户最近一次登录信息
ding@ding-server:~$ lastlog
Username Port From Latest
root **Never logged in**
daemon **Never logged in**
bin **Never logged in**
ding pts/0 10.94.5.157 Thu May 26 16:22:44 +0800 2022
hi2 pts/2 10.94.5.157 Tue May 24 17:14:46 +0800 2022
hi **Never logged in**
hahaha pts/3 10.94.5.157 Tue May 24 17:37:50 +0800 2022
hello **Never logged in**
不包括切换用户。
¶ split - 文件切分
split [选项] 文件 [前缀]
... | split [选项] [前缀]
如不指定前缀,生成文件名如:xaa xab xac …;指定前缀,会用前缀替换 x。
选项:
-b 字节数:切分为特定字节大小的文件(会无条件断开,在中文字符内断开会导致乱码)-C 字节数:切分为特定字节大小的文件,但不会把一行断开-l 行数:以特定行数进行切分
¶ 例 1
split_t.txt 内容:
1234567
8901234
5678901
2345678
9012345
6789012
3456789
0123456
7890123
4567890
1234567
ding@ding-server:~/regex_test/split$ split -b 20 split_t.txt
ding@ding-server:~/regex_test/split$ ls -l
total 24
-rw-rw-r-- 1 ding ding 88 May 25 16:17 split_t.txt
-rw-rw-r-- 1 ding ding 20 May 25 16:25 xaa
-rw-rw-r-- 1 ding ding 20 May 25 16:25 xab
-rw-rw-r-- 1 ding ding 20 May 25 16:25 xac
-rw-rw-r-- 1 ding ding 20 May 25 16:25 xad
-rw-rw-r-- 1 ding ding 8 May 25 16:25 xae
ding@ding-server:~/regex_test/split$ cat xaa
1234567
8901234
5678ding@ding-server:~/regex_test/split$ cat xab
901
2345678
9012345
ding@ding-server:~/regex_test/split$
¶ 例 2
split_t.txt 内容同上。
ding@ding-server:~/regex_test/split$ split -C 20 split_t.txt st_
ding@ding-server:~/regex_test/split$ ls -l
total 28
-rw-rw-r-- 1 ding ding 88 May 25 16:17 split_t.txt
-rw-rw-r-- 1 ding ding 16 May 25 16:26 st_aa
-rw-rw-r-- 1 ding ding 16 May 25 16:26 st_ab
-rw-rw-r-- 1 ding ding 16 May 25 16:26 st_ac
-rw-rw-r-- 1 ding ding 16 May 25 16:26 st_ad
-rw-rw-r-- 1 ding ding 16 May 25 16:26 st_ae
-rw-rw-r-- 1 ding ding 8 May 25 16:26 st_af
ding@ding-server:~/regex_test/split$ cat st_aa
1234567
8901234
ding@ding-server:~/regex_test/split$ cat st_ab
5678901
2345678
ding@ding-server:~/regex_test/split$
¶ 例 3
split_t.txt 内容:
这是一个文本示例。但是我不知道会如何。总而言之,我不知道到底发生了什么。
ding@ding-server:~/regex_test/split$ split -b 20 split_t.txt
ding@ding-server:~/regex_test/split$ ls -l
total 28
-rw-rw-r-- 1 ding ding 88 May 25 16:17 split_t.txt
-rw-rw-r-- 1 ding ding 20 May 25 16:29 xaa
-rw-rw-r-- 1 ding ding 20 May 25 16:29 xab
-rw-rw-r-- 1 ding ding 20 May 25 16:29 xac
-rw-rw-r-- 1 ding ding 20 May 25 16:29 xad
-rw-rw-r-- 1 ding ding 20 May 25 16:29 xae
-rw-rw-r-- 1 ding ding 9 May 25 16:29 xaf
ding@ding-server:~/regex_test/split$ cat xaa
这是一个文本�ding@ding-server:~/regex_test/split$ cat xab
�例。但是我不�ding@ding-server:~/regex_test/split$
¶ tr - 替换、压缩、删除
... | tr [选项] 第一字符集 [第二字符集]
选项:
- 不加选项:替换
cat a.txt | tr ad AD # 将文件中的 a 替换为 A,d 替换为 D 输出 cat a.txt | tr adc AD # 第一字符集长于第二字符集时,长出来的部分替换为第二字符集最后一个字符 -c:替换所有不属于第一字符集的字符cat a.txt | tr -c ad A # 将文件中的 a、d 之外的字符(包括换行符)替换为 A 输出 cat a.txt | tr -c ad AD # 第二字符集多于一个字符时,以最后一个字符为准-d:删除所有属于第一字符集的字符(此时不需要第二字符集)cat a.txt | tr -d ad # 将文件中的 a、d 删除输出(换行符会保留) cat a.txt | tr -cd ad AD # 将文件中的 a、d 之外的字符(包括换行符)删除输出-s:将连续重复的字符以单独一个字符显示(此时不需要第二字符集)cat a.txt | tr -s a # 将文件中的连续重复的 a 缩为一个输出-t:忽略第一字符集较第二字符集多出的字符,然后替换cat a.txt | tr -t adc AD # 将文件中的 a 替换为 A,d 替换为 D 输出(c 不管)
¶ xargs - 参数代换
适用于不支持标准输入的命令。
xargs [选项] 命令
选项:
-eEOF:当xargs读到EOF时停止(要连写)-p:执行指令前询问(输入y才执行)-n 整数:每次执行命令时需要的参数个数-0:如果输入的参数含有特殊字符,将其还原为一般字符,用于特殊状态
例:
ding@ding-server:~$ cat /etc/passwd | cut -d ':' -f 1 | id
uid=1000(ding) gid=1000(ding) groups=1000(ding) # 只输出了自己的信息,实际上就是执行 id
ding@ding-server:~$ cat /etc/passwd | cut -d ':' -f 1 | xargs id
id: extra operand ‘daemon’ # 如不指定 -n,则会把全部信息传过去当参数
Try 'id --help' for more information.
ding@ding-server:~$ cat /etc/passwd | cut -d ':' -f 1 | xargs -n 1 id
uid=0(root) gid=0(root) groups=0(root),117(docker)
uid=1(daemon) gid=1(daemon) groups=1(daemon)
uid=2(bin) gid=2(bin) groups=2(bin)
... # 相当于 id 用户名 执行多次,每次为一个用户名
uid=1003(hello) gid=1003(hello) groups=1003(hello)
# 执行到 games 停止
ding@ding-server:~$ cat /etc/passwd | cut -d ':' -f 1 | xargs -n 1 -egames id
uid=0(root) gid=0(root) groups=0(root),117(docker)
uid=1(daemon) gid=1(daemon) groups=1(daemon)
uid=2(bin) gid=2(bin) groups=2(bin)
...
uid=5(games) gid=60(games) groups=60(games)
¶ printf - 格式化输出内容
printf 格式 内容1 内容2 ...
printf 格式 $(包含内容的标准输入)
格式最好用单引号包裹。
常见的特殊样式:
\n:换行\t:Tab 键\xNN:NN为两位数字,为 UTF-8 编码
常见的变量格式:
%ns:字符串,n可选,代表多少个字符。如果字符串长度小于n,则会靠右对齐%ni或%nd:整数,n可选,表示多少位整数。如果整数位数小于n,则会靠右对齐%N.nf:浮点数(小数),N.n可选,N表示整数加小数的位数,n表示保留的小数位数(四舍六入五取偶)- 如果总位数小于
N,则会右对齐 - 填写
.后,N可选,n如未填则为0;不填写N.n时,默认n为6
例:
score.txt 内容:
name chinese english math average
dmtsai 80 60 92 77.33
vbird 75 55 80 70.00
ken 60 90 70 73.33
ding@ding-server:~$ printf '%s\t%s\t%s\t%s\t%s\t\n' $(cat score.txt)
name chinese english math average
dmtsai 80 60 92 77.33
vbird 75 55 80 70.00
ken 60 90 70 73.33
ding@ding-server:~$ printf '%10s %5i %5i %5i %8.2f\n' $(cat score.txt | grep -v name)
dmtsai 80 60 92 77.33
vbird 75 55 80 70.00
ken 60 90 70 73.33
ding@ding-server:~$ printf '\x70\x72\x69\x6E\x74\x66\n'
printf
ding@ding-server:~$ printf '\xE6\xA0\xBC\xE5\xBC\x8F\xE5\x8C\x96\xE8\xBE\x93\xE5\x87\xBA\n'
格式化输出
¶ 语系
¶ 查看与设置语系
Linux 中根据 locale 相关环境变量定义语系,包括语言、字符集、区域、时间、单位、排序等格式。
执行 locale 查看当前语系相关的环境变量。
ding@ding-server:~$ locale
LANG=en_US.UTF-8
LANGUAGE=
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
可更改对应的环境变量来定义语系。一般会更改 LANG 或 LC_ALL。
较常用的值:C(有人说建议使用 C.UTF-8)、en_US.UTF-8、zh_CN.UTF-8。
¶ 添加语系
执行 locale -a 查看目前开启的语系。
Ubuntu 下,root 权限执行 locale-gen 语系 开启语系。
ding@ding-server:~$ locale -a
C
C.UTF-8
en_US.utf8
POSIX
ding@ding-server:~$ locale-gen zh_CN.UTF-8
Generating locales (this might take a while)...
zh_CN.UTF-8... done
Generation complete.
ding@ding-server:~$ locale -a
C
C.UTF-8
en_US.utf8
POSIX
zh_CN.utf8
设置 en_US.UTF-8、C、zh_CN.UTF-8 三种语系后,系统一些功能的对比如下:
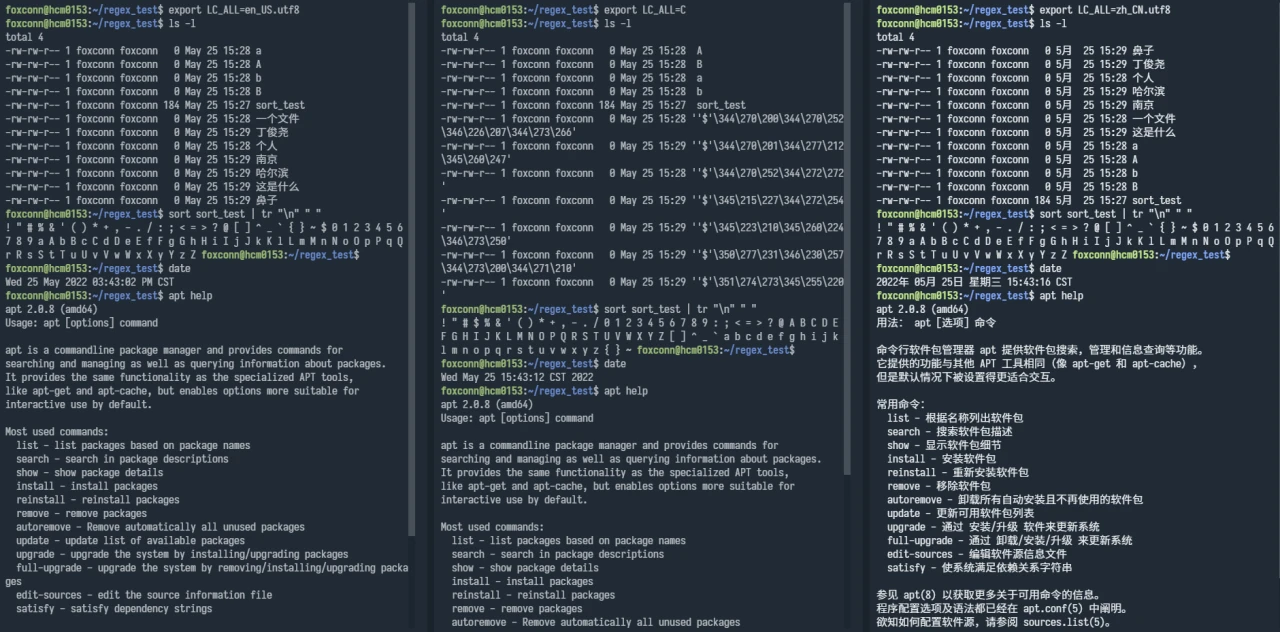
¶ 默认语系为什么设置为英文
尽管能够设置语系以设置语言,且通过 SSH 也能够传输、显示中文,但考虑到控制台中无法正确显示非 ASCII 字符(需要用到控制台的情况,通常是系统发生故障需要修复),故默认情况下一般仍然设置为英文。
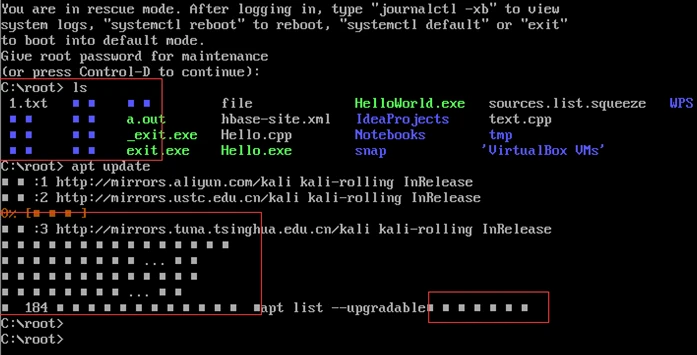
¶ 语系对排序和正则表达式的影响
以键盘上的字母符号为例,使用 | sort | tr "\n" " " 排序
LANG=C 时的排序,与 ASCII 排序相同(有顺序部分以 … 省略,下同):
! " # $ % & ' ( ) * + , - . / 0 ... 9 : ; < = > ? @ A ... Z [ ] ^ _ ` a ... z { } ~
LANG=en_US.UTF-8 或 LANG=zh_CN.UTF-8 时的排序:
! " # % & ' ( ) * + , - . / : ; < = > ? @ [ ] ^ _ ` { } ~ $ 0 ... 9 a A b B ... z Z
ls、grep 在使用正则表达式时暂未发现影响,但文档中有提及需注意语系对结果的影响。
保险起见,接下来的例子仍然按照
LANG=C处理。
¶ 正则表达式
regex; regexp(Regular Expression),对文本进行过滤的工具。
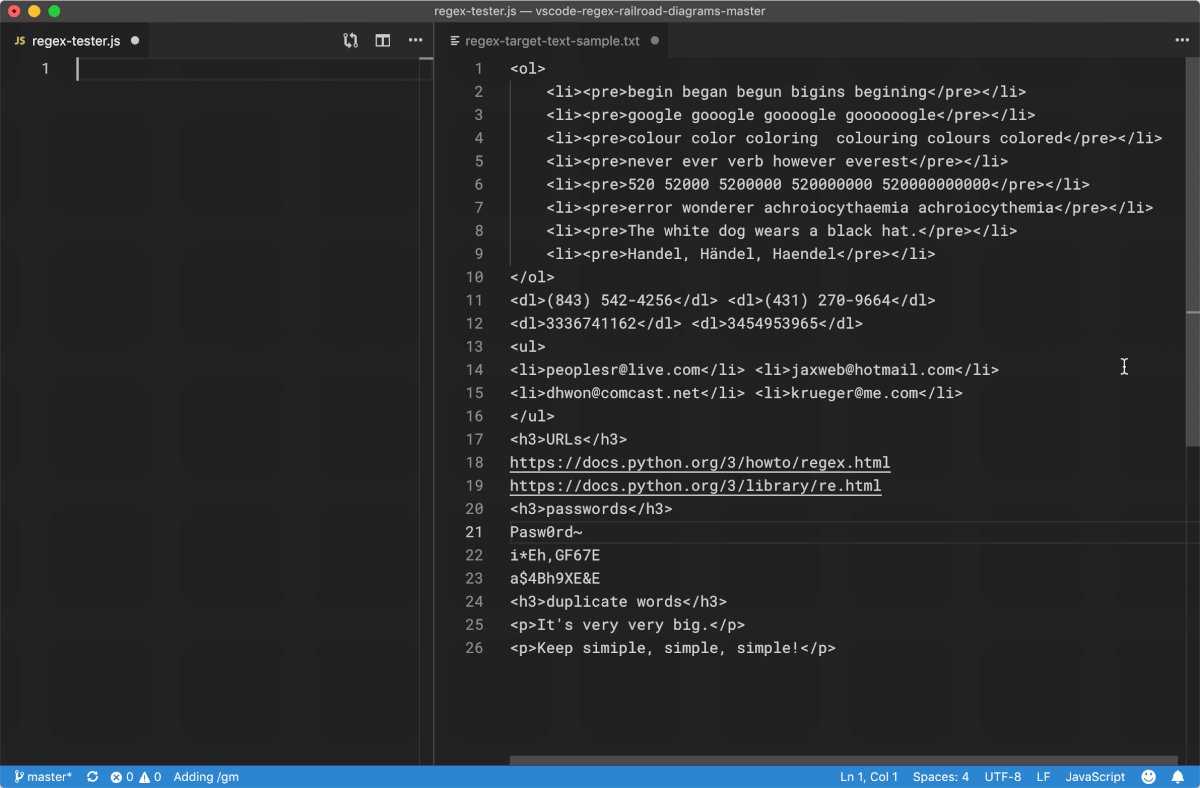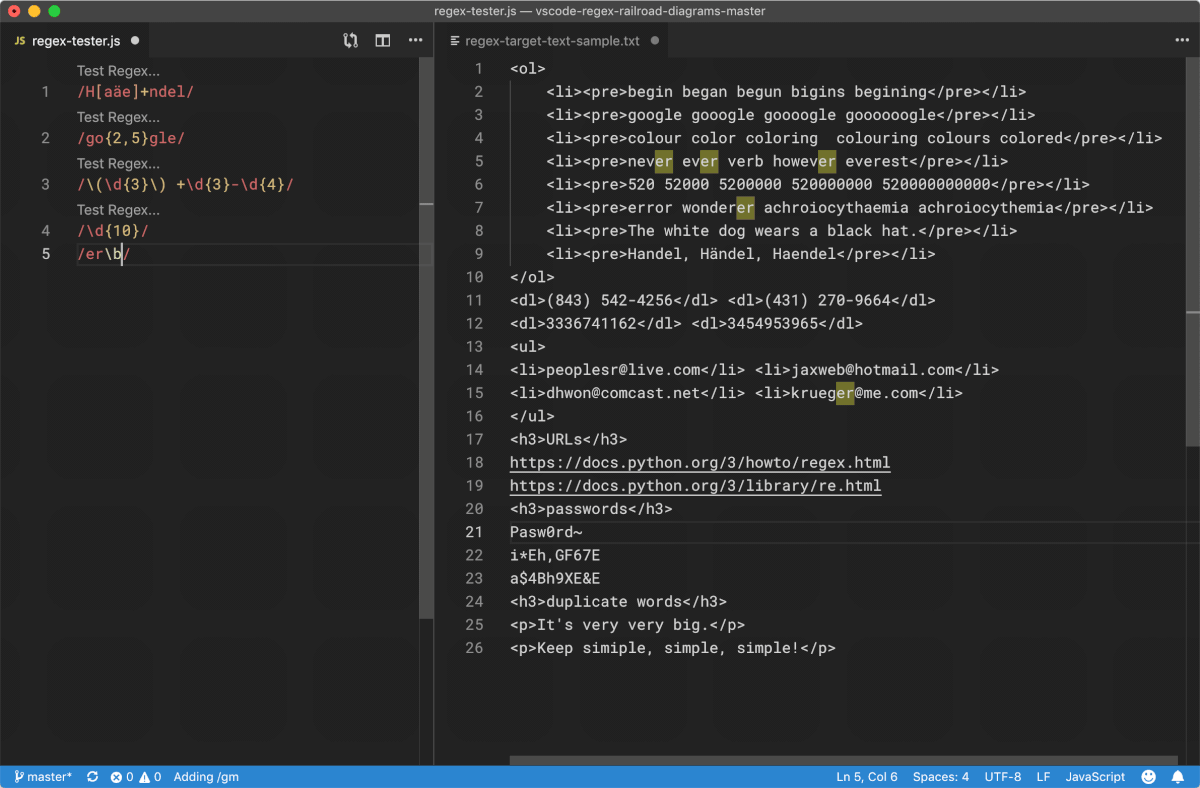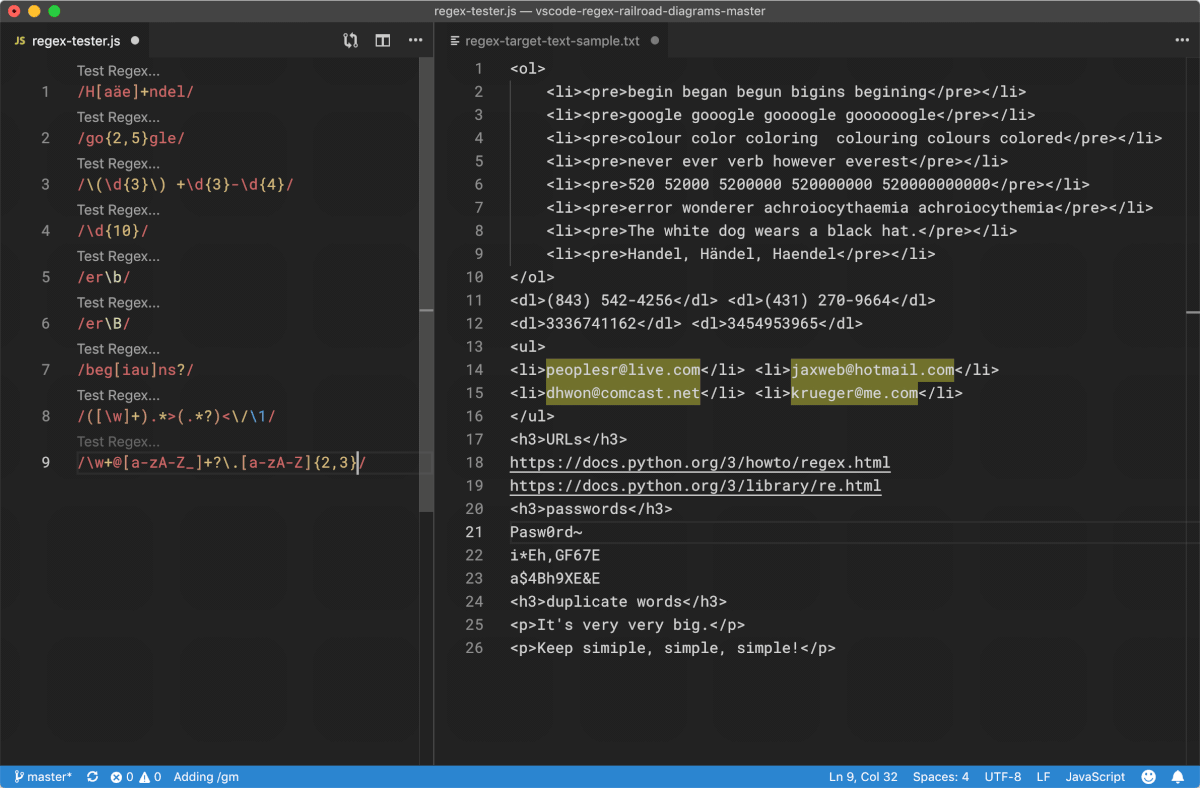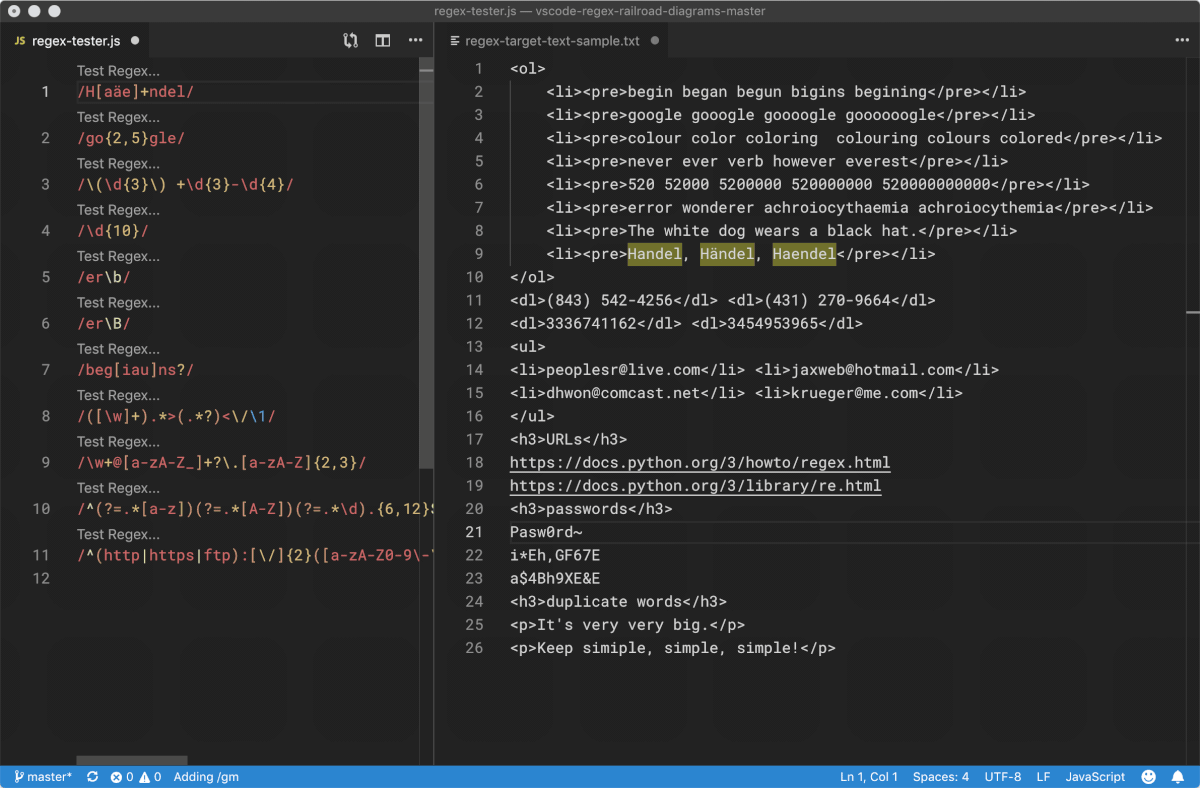
¶ 正则表达式的主要用途
- 从文本中提取内容
- 检测用户输入是否正确
¶ grep 支持的正则表达式语法分类
- 基础正则表达式
- 扩展正则表达式
要使用grep -E或egrep,或转义特殊字符 - Perl 正则表达式
要使用grep -P
前两者为 POSIX 标准定义的语法。
¶ 匹配单个字符
| 含义 | 表达式 |
|---|---|
| 匹配确定的某个字符 | a b c 1 2 3 + - = … |
| 匹配任意单个字符 | . |
| 匹配特殊字符 | \元字符转义 |
| 匹配多个字符(字符集)中某一个 | [字符集内容] |
| 利用字符集合区间表示 | [a-z] [A-Z] [0-9] |
| 排除 | [^字符集内容] |
¶ 元字符
¶ 表示位置
| 含义 | 表达式 |
|---|---|
| 匹配一行行首 | ^ |
| 匹配一行行尾 | $ |
| 匹配空行 | ^$ |
| 匹配单词边缘的空字符串 | \b |
| 匹配单词边缘的非空字符串 | \B |
| 匹配单词左边缘 | \< |
| 匹配单词右边缘 | \> |
¶ 匹配特定字符
| 含义 | 表达式 |
|---|---|
| 字母数字元字符 | \w |
| 非字母数字元字符 | \W |
| 空白字符 | \s |
| 非空白字符 | \S |
¶ POSIX 字符集
| 含义 | 表达式 | 等价于 |
|---|---|---|
| 所有字母和数字 | [:alnum:] |
0-9a-zA-Z |
| 所有数字 | [:digit:] |
0-9 |
| 所有字母 | [:alpha:] |
a-zA-Z |
| 大写字母 | [:upper:] |
A-Z |
| 小写字母 | [:lower:] |
a-z |
| 空白(空格、Tab) | [:blank:] |
|
| 非空字符 | [:graph:] |
|
| 标点符号 | [:punct:] |
使用时视为单字对待,如 [[:alpha:]] == [a-zA-Z]。
不受语系影响,但其他地方基本上不能使用。
¶ 扩展正则表达式匹配
匹配任意一个字符串:(string1|string2) (string1|string2|string3) …,其中括号表示组合,| 表示或。
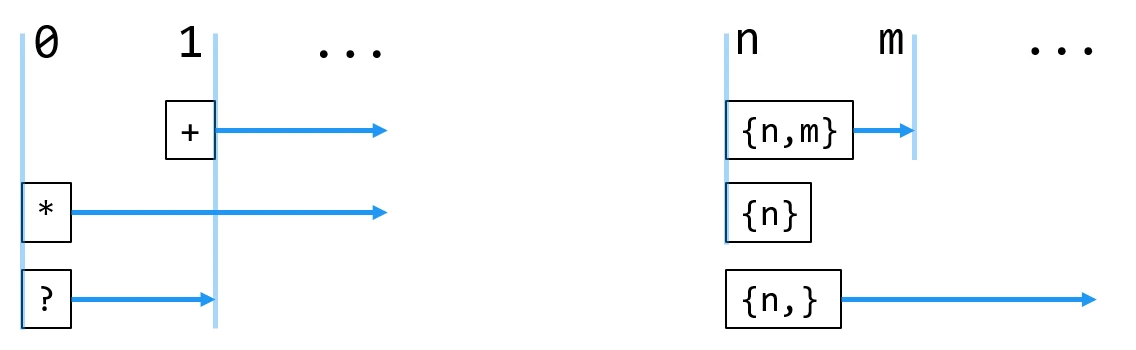
重复匹配之前的字符若干次:
| 次数 | 表达式 |
|---|---|
+ |
|
* |
|
? |
|
{n,m} |
|
{n} |
|
{n,} |
¶ Perl 正则表达式元字符
| 含义 | 表达式 |
|---|---|
| 数字元字符 | \d |
| 非数字元字符 | \D |
¶ 正则表达式运算优先级
\,转义[],方括号表达式(),分组*+?{},限定符- 普通字符,按照从左到右的顺序
^$,定位符|,或运算
¶ 例:提取 IPv4 地址
¶ 背景
使用 ip addr 可以显示各网络设备的 IP 信息。
ding@ding-server:~$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:10:02:ec brd ff:ff:ff:ff:ff:ff
inet 10.94.0.153/21 brd 10.94.7.255 scope global ens160
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe10:2ec/64 scope link
valid_lft forever preferred_lft forever
...
以设备 ens160 为例, 10.94.0.153 为其 IPv4 地址。
我们需要提取出系统中所有的 IPv4 地址。
¶ 第一步:初步筛选
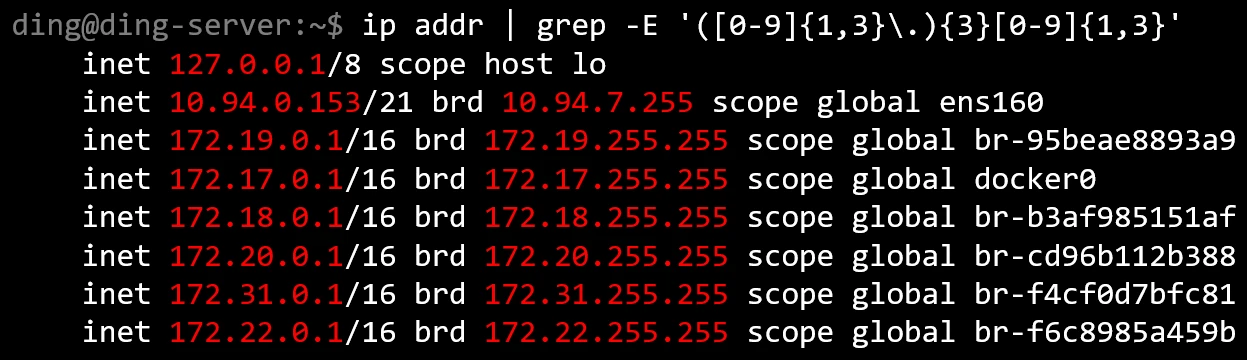
首先写出以下正则表达式:
([0-9]{1,3}\.){3}[0-9]{1,3}
含义图解:

即:找到以下字符串,它
- 首先有一个重复三次的组合,该组合的格式为:
- 数字重复 1~3 次
- 后接
. - 然后有数字重复 1~3 次
结果:
¶ 第二步:去掉广播地址
上一步得到的结果中包含广播地址,我们不需要。
故写出以下正则表达式:
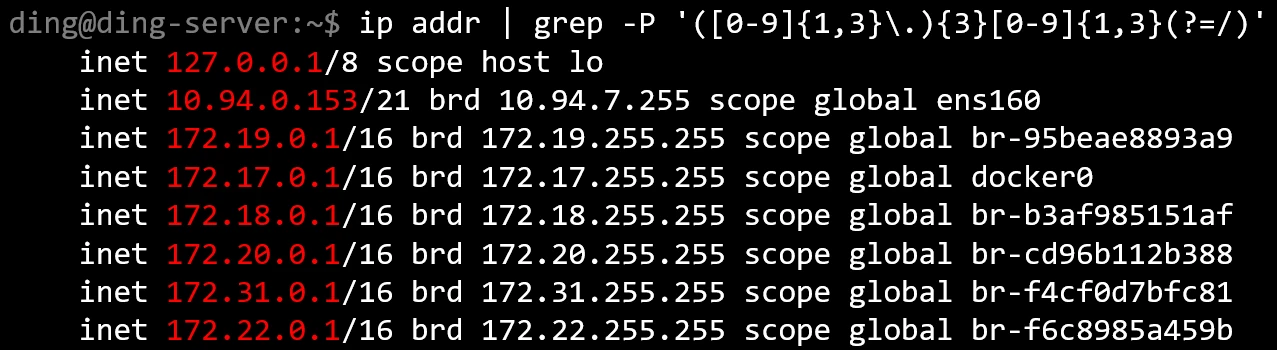
([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)
含义图解:

即:找到以下字符串,它
- 首先有一个重复三次的组合,该组合的格式为:
- 数字重复 1~3 次
- 后接
. - 然后有数字重复 1~3 次
- 这个字符串后面有
/,但是不计入字符串
由于添加了 (?=/),这个正则表达式属于 Perl 正则表达式,故使用 grep 时需要添加 -P 选项。
结果:
¶ 优化
输出特定连接的 IP 地址:
ding@ding-server:~$ ip addr show ens160 | grep -Po '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)'
10.94.0.153
自动识别以太网的连接,输出其 IP 地址:
ding@ding-server:~$ ip addr show $(ip addr | grep -E '^[0-9]+' | grep -Eo 'ens\w+') | grep -Po '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)'
10.94.0.153
想要不带颜色,可以设置选项 --color=never。
¶ 更加准确的表达式
可以用于验证输入的 IP 地址是否正确。
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}

¶ 正则表达式相关工具与参考
¶ Linux 三剑客
¶ grep - 强大的文本内容查找工具
Global Regular Expression Print
此前已讲过相关的用法,这里仅作补充。
选项:
-B 数字:除了列出选定行,同时列出前面(before)的若干行-A 数字:除了列出选定行,同时列出后面(after)的若干行
¶ 例
查看系统日志的一种方法:
journalctl -xe
在其中过滤出内容:
journalctl -xe | grep var-lib-docker-containers
但有些日志是多行的,而且还要看上下文内容;但是完整的日志太长了:
-- The unit UNIT has successfully entered the 'dead' state.
May 26 14:04:51 hcm0153 systemd[1]: var-lib-docker-containers-87d27a39054d9570218c059448c8b6859f31788c0bf78be731006116c1475a6b-mounts-shm.mount: Succeeded.
-- Subject: Unit succeeded
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
如何处理?
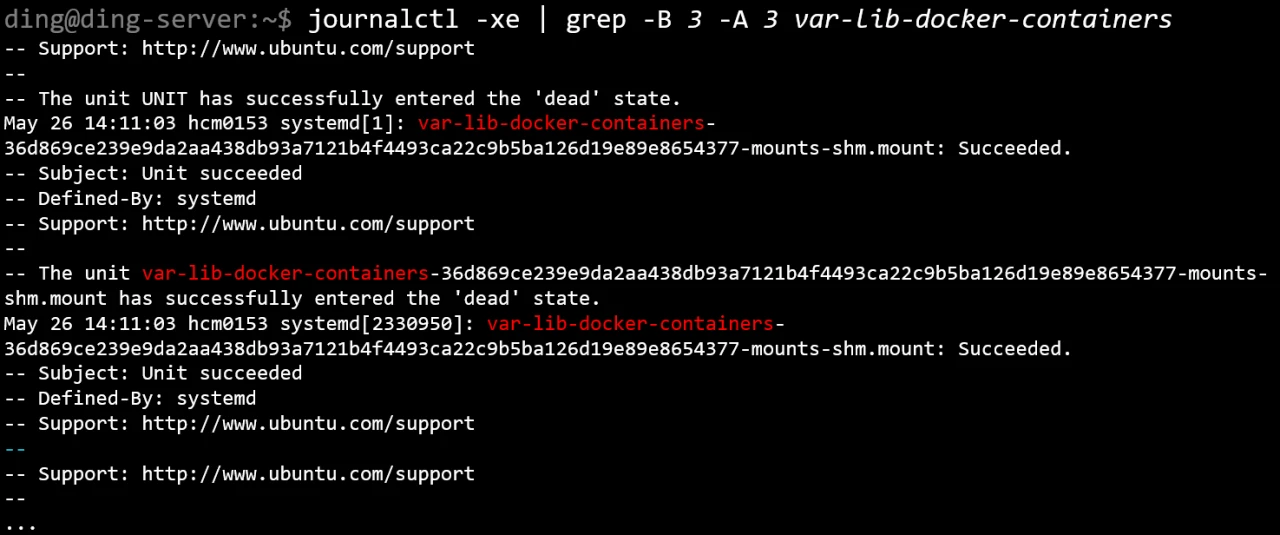
使用 grep 可以显示前后若干行:
ding@ding-server:~$ journalctl -xe | grep -B 3 -A 3 var-lib-docker-containers
-- Support: http://www.ubuntu.com/support
--
-- The unit UNIT has successfully entered the 'dead' state.
May 26 14:11:03 hcm0153 systemd[1]: var-lib-docker-containers-36d869ce239e9da2aa438db93a7121b4f4493ca22c9b5ba126d19e89e8654377-mounts-shm.mount: Succeeded.
-- Subject: Unit succeeded
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- The unit var-lib-docker-containers-36d869ce239e9da2aa438db93a7121b4f4493ca22c9b5ba126d19e89e8654377-mounts-shm.mount has successfully entered the 'dead' state.
May 26 14:11:03 hcm0153 systemd[2330950]: var-lib-docker-containers-36d869ce239e9da2aa438db93a7121b4f4493ca22c9b5ba126d19e89e8654377-mounts-shm.mount: Succeeded.
-- Subject: Unit succeeded
-- Defined-By: systemd
-- Support: http://www.ubuntu.com/support
--
-- Support: http://www.ubuntu.com/support
--
...
实际上,不同段之间有有颜色的线:
¶ sed - 文本的流编辑器
Stream Editor
非交互式文本编辑器,从文件或标准输入中每次读取一行数据复制到缓冲区里,然后读取命令行或脚本的编辑子命令,对缓冲区的文本进行编辑。
在缓冲区处理,不是真正地处理文件;可以用选项使其存到文件。
适用于:
- 非常大的文本文件,使用交互式文本编辑器操作非常慢
- 编辑命令比较复杂,在普通编辑器内难以完成
- 扫描一个大文件,并且需要经过一系列的操作
- 不便于使用一般的文本编辑器的情况(如脚本执行中更改文件内容、特殊环境无法安装文本编辑器)
sed [选项] 子命令 文件
... | sed [选项] 子命令
选项:
-n:安静模式,只输出处理的部分(否则会把处理后的文档打印出来)-e:直接在命令行模式上进行sed的操作编辑(默认选项)-f:将 sed 的操作输出为一个文件-f 文件名:传入sed操作文件,执行文件里的sed操作-r:支持扩展正则(默认是基础正则)-i:直接修改,而非输出到屏幕(请谨慎使用!)
¶ 子命令
a:追加sed '1a hello world' # 在第一行后面追加一行内容 hello worldc:替换行sed '1c 123' # 将第一行内容替换为 123 sed '1,2c hello world' # 将第一、二行内容替换为一行,为 123i:插入sed '1i xxx' # 在第一行前面插入一行内容 xxx sed '2,3i xxxx' # 在第 2、3 行前面各插入一行内容 xxxxd:删除sed '1d' # 删除第一行 sed '1,2d' # 删除第一、二行 sed '1~2d' # 从第一行开始,步长为 2 的行删掉(含第一行),即删掉 1、3、5、7... 行,保留 2、4、6、8... 行(删除奇数行) sed '0~2d' # 从第零行开始,步长为 2 的行删掉,即删掉 2、4、6、8... 行,保留 1、3、5、7... 行(删除偶数行) sed '7,+3d' # 删掉 7~10 行 sed '$d' # 删掉最后一行 sed '2,$d' # 删掉第 2 行到最后一行p:打印(一般需要搭配-n选项,否则会在输出原先文档时,重复输出对应行)sed -n '2,$p' # 输出从第 2 行到最后的内容s:替换字符(如加上-n选项,不会输出内容;内容末尾加入p,加上-n选项,才会只输出更改的行)sed 's/xxx/yyy/g' sed -n 's/xxx/yyy/gp' # 这样会输出更改的行 sed 's:xxx:yyy:g' # 分隔符可以改成冒号
¶ 例
ding@ding-server:~$ ip addr | grep -P '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)'
inet 127.0.0.1/8 scope host lo
inet 10.94.0.153/21 brd 10.94.7.255 scope global ens160
inet 172.19.0.1/16 brd 172.19.255.255 scope global br-95beae8893a9
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
inet 172.18.0.1/16 brd 172.18.255.255 scope global br-b3af985151af
inet 172.20.0.1/16 brd 172.20.255.255 scope global br-cd96b112b388
inet 172.31.0.1/16 brd 172.31.255.255 scope global br-f4cf0d7bfc81
inet 172.22.0.1/16 brd 172.22.255.255 scope global br-f6c8985a459b
ding@ding-server:~$ ip addr | grep -P '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)' | sed 's/^.*inet //g'
127.0.0.1/8 scope host lo
10.94.0.153/21 brd 10.94.7.255 scope global ens160
172.19.0.1/16 brd 172.19.255.255 scope global br-95beae8893a9
172.17.0.1/16 brd 172.17.255.255 scope global docker0
172.18.0.1/16 brd 172.18.255.255 scope global br-b3af985151af
172.20.0.1/16 brd 172.20.255.255 scope global br-cd96b112b388
172.31.0.1/16 brd 172.31.255.255 scope global br-f4cf0d7bfc81
172.23.0.1/16 brd 172.23.255.255 scope global br-359c2aecf51c
ding@ding-server:~$ ip addr | grep -P '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)' \
> | sed 's/^.*inet //g' | sed 's/\/.*$//g' # 输出所有连接的 IP 地址
127.0.0.1
10.94.0.153
172.19.0.1
172.17.0.1
172.18.0.1
172.20.0.1
172.31.0.1
172.23.0.1
ding@ding-server:~$ ip addr show ens160 | grep -P '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)' \
> | sed 's/^.*inet //g' | sed 's/\/.*$//g' # 输出特定连接的 IP 地址
10.94.0.153
ding@ding-server:~$ ip addr show $(\
> ip addr | grep -E '^[0-9]+' | sed 's/^[0-9]*: //g' | sed 's/:.*$//g' | grep ens \
> ) | grep -P '([0-9]{1,3}\.){3}[0-9]{1,3}(?=/)' \
> | sed 's/^.*inet //g' | sed 's/\/.*$//g' # 自动识别以太网的连接,输出其 IP 地址
10.94.0.153
¶ awk - 强大的数据处理工具
Alfred Aho, Peter Weinberger, Brian Kernighan 三人的姓氏首字母
是一种强大的数据处理工具,也是一种编程环境。
与 sed 的区别:sed 常常作用于一整行的处理,而 awk 倾向于一行当中分成数个字段来处理。
awk [选项] '条件类型1{操作1} 条件类型2{操作2} ...' 文件
... | awk [选项] '条件类型1{操作1} 条件类型2{操作2} ...'
选项:
-F fs:指定输入分隔符,fs是字符串或正则表达式-v 变量名=值:赋值一个用户自定义变量,将外部变量传给awk-f 文件:从脚本文件中读取awk命令
¶ 提取数据
如:使用 last 命令查看登录记录:
ding@ding-server:~$ last
foxconn pts/0 10.94.5.157 Thu May 26 16:22 still logged in
foxconn pts/0 10.94.5.188 Thu May 26 15:10 - 15:17 (00:07)
reboot system boot 5.4.0-110-generi Mon May 23 13:59 still running
reboot system boot 5.4.0-110-generi Thu May 12 15:50 - 13:58 (10+22:08)
...
foxconn tty1 Fri Apr 1 18:08 - down (00:04)
reboot system boot 5.4.0-107-generi Fri Apr 1 18:07 - 18:12 (00:05)
wtmp begins Fri Apr 1 18:07:21 2022
对于一行,默认字段分隔符为 空格 或 Tab。
每一列都有变量名称:

输出数据有 print 和 printf:
print 内容1 内容2 内容3 ...
printf 格式,内容1,内容2,内容3,...
由此:
取出账号与登录者的 IP,中间用 Tab 隔开:
ding@ding-server:~$ last | awk '{print $1 "\t" $3}'
foxconn 10.94.5.157
foxconn 10.94.5.188
reboot boot
reboot boot
...
foxconn Fri
reboot boot
wtmp Fri
由于重启、在 tty 的登录记录格式和其他的不一样,故直接放进去,这些行的数据会有异常。故使用 awk 需要注意数据是否为连续的。
¶ 处理过程
- 读入第一行,并将其数据写入
$0、$1、$2… 等变量中 - 根据条件类型的限制,判断是否需要进行后面的操作
- 完成所有操作与条件类型
- 若还有行未读,重复上面三步,直到读完
¶ 内置变量
处理时有内置变量如下,调用不需要 $:
NF:每一行拥有的字段数NR:目前awk处理的数据是第几行的FS:目前的分隔字符(默认是 空格)
ding@ding-server:~$ last | awk '{print $1 "\t ln: " NR "\t col: " NF}'
foxconn ln: 1 col: 10
foxconn ln: 2 col: 10
reboot ln: 3 col: 10
reboot ln: 4 col: 11
...
foxconn ln: 295 col: 9
reboot ln: 296 col: 11
ln: 297 col: 0
wtmp ln: 298 col: 7
ln: 10 col: 0
¶ 逻辑判断
使用一般的逻辑判断方式即可。
ding@ding-server:~$ last | awk 'NF == 10 && $1 != "reboot" {print $1 "\t" $3}'
foxconn 10.94.5.157
hello 10.94.5.157
foxconn 10.94.5.188
hello 10.94.5.157
foxconn :pts/1:S.0
foxconn 10.94.5.188
foxconn :pts/1:S.0
foxconn :pts/1:S.0
foxconn tmux(1523669).%2
foxconn tmux(1523669).%1
foxconn tmux(1523669).%0
hello tmux(1522140).%3
hello tmux(1522140).%2
hello tmux(1522140).%1
hello tmux(1522140).%0
hello tmux(1522110).%0
...
¶ 关键词
在子命令中定义分隔符为 :,读取 UID < 10 的用户名:
ding@ding-server:~$ cat /etc/passwd | awk '{FS=":"} $3 < 10 {print $1 "\t" $3}'
root:x:0:0:root:/root:/bin/bash
daemon 1
bin 2
sys 3
sync 4
games 5
man 6
lp 7
mail 8
news 9
第一行出现问题的原因:定义 FS 时已经读入了第一行,并采用默认分隔符分隔,故定义的分隔符只能在第二行开始生效。
可以利用 BEGIN 关键词,在读入前即定义好变量:
ding@ding-server:~$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t" $3}'
root 0
daemon 1
bin 2
sys 3
sync 4
games 5
man 6
lp 7
mail 8
news 9
此外还有 END 关键词。
¶ 计算
输出内存占用百分比:
ding@ding-server:~$ free | awk '$1=="Mem:" {print ($3 / $2) * 100 "%"}'
59.6712%
ding@ding-server:~$ free | awk '$1=="Mem:" {printf "%.2f%%\n",($3 / $2) * 100 }'
59.65%
¶ 比较复杂的脚本
score.txt 内容:
# 本行实际上不存在,仅仅是为了显示第一行的空格而添加
name chinese english math
dmtsai 80 60 92
vbird 75 55 80
ken 60 90 70
ding@ding-server:~$ awk '
> NR == 1 {
> printf "%6s\t%7s\t%7s\t%4s\t%5s\t%7s\n",$1,$2,$3,$4,"total","average"
> }
> NR > 1 {
> total = $2 + $3 + $4
> average = total / 3
> printf "%6s\t%7d\t%7d\t%4d\t%5d\t%7.2f\n",$1,$2,$3,$4,total,average
> }' score.txt
name chinese english math total average
dmtsai 80 60 92 232 77.33
vbird 75 55 80 210 70.00
ken 60 90 70 220 73.33
可以存为脚本文件执行,如 awktest.awk 内容如下:
NR == 1 {
printf "%6s\t%7s\t%7s\t%4s\t%5s\t%7s\n",$1,$2,$3,$4,"total","average"
}
NR > 1 {
total = $2 + $3 + $4;
average = total / 3;
printf "%6s\t%7d\t%7d\t%4d\t%5d\t%7.2f\n",$1,$2,$3,$4,total,average
}
ding@ding-server:~$ awk -f awktest.awk score.txt
name chinese english math total average
dmtsai 80 60 92 232 77.33
vbird 75 55 80 210 70.00
ken 60 90 70 220 73.33
¶ 练习
在前面的基础上,在最后一行输出这几个人各列的平均分。
参考答案
BEGIN {
chinese_sum = 0
english_sum = 0
math_sum = 0
total_sum = 0
average_sum = 0
}
NR == 1 {
printf "%7s\t%7s\t%7s\t%5s\t%5s\t%7s\n",$1,$2,$3,$4,"total","average"
}
NR > 1 {
total = $2 + $3 + $4
average = total/3
chinese_sum += $2
english_sum += $3
math_sum += $4
total_sum += total
average_sum += average
printf "%7s\t%7d\t%7d\t%5d\t%5d\t%7.2f\n",$1,$2,$3,$4,total,average
}
END {
chinese_avg = chinese_sum / (NR - 1)
english_avg = english_sum / (NR - 1)
math_avg = math_sum / (NR - 1)
total_avg = total_sum / (NR - 1)
average_avg = average_sum / (NR - 1)
printf "%7s\t%7.2f\t%7.2f\t%5.2f\t%5.2f\t%7.2f\n","average",chinese_avg,english_avg,math_avg,total_avg,average_avg
}
执行结果(设脚本文件名为 awktest.awk):
ding@ding-server:~$ awk -f awktest.awk score.txt
name chinese english math total average
dmtsai 80 60 92 232 77.33
vbird 75 55 80 210 70.00
ken 60 90 70 220 73.33
average 71.67 68.33 80.67 220.67 73.56
¶ 补充资料
¶ 参考资料
- 鸟哥的Linux私房菜. 基础学习篇 / 鸟哥著 ; Linux 中国繁转简. – 4版. – 北京 : 人民邮电出版社, 2018.3; ISBN 978-7-115-47258-8
- Linux就该这么学 / 刘遄著. – 北京 : 人民邮电出版社, 2017.11; ISBN 978-7-115-47031-7
- Linux 教程 | 菜鸟教程
- ”A Question Of Rounding” in issue #143
- linux终端中文方块,如何解决在Linux CLI终端界面中汉字方块乱码_weixin_39782832的博客-CSDN博客
- Confusion with grep & locale?
- linux - How can I make ”ls” show dotfiles first? - Super User
- Character Classes and Bracket Expressions (GNU Grep 3.7)
- @xiaolai’s works
- linux提取正则表达式字符串 - CSDN
- 正则表达式在线测试 | 菜鸟工具
- Regexper