配置、数据文件格式介绍
约 2859 个字 768 行代码 6 张图片 预计阅读时间 19 分钟
Info
这里默认以 Python 及基于此的模块介绍文件格式的读写、转换
如无特殊说明,均为默认情况,暂不考虑对解析器的定制
为什么用文件记录配置、数据?
- 与代码分离,便于部署
- 便于记录数据
- 便于不同程序之间交换
为什么用特定的文本文件格式?
- 有现成的解析工具
- 编辑器支持
- 文本格式便于编辑
常见的文件格式:
- CSV(
.csv) - INI (
.ini、.conf、...) - JSON (
.json) - YAML (
.yaml、.yml) - TOML (
.toml) - XML (
.xml)
CSV
逗号分隔值(Comma-Separated Values)
格式示例
-
实际上相当于表格,存储的是二维及以下的数据:
desc date 缺失1 缺失2 缺失3 缺失4 改善1 改善2 改善3 改善4 逾期1 逾期2 逾期3 逾期4 初始 3 0 1 1 0 0 0 0 0 0 0 0 13: 事业群1, D4.1, 一般, 延期 2023/1/1 0:00 3 0 1 1 0 0 0 0 1 0 0 0 12: 事业群2, D4.1, ""主要"", 延期 2023/1/1 0:00 3 0 1 1 0 0 0 0 1 0 0 0 11: 事业群1, D4.1, 关键, 关闭 2020/1/1 0:00 3 0 1 1 1 0 0 0 1 0 0 0 10: 事业群2, C5.1, 风险, 关闭 2020/1/1 0:00 3 0 1 1 1 0 0 0 1 0 0 0 7: 事业群1, C5.1, 一般, 延期 2023/1/1 0:00 3 0 1 1 1 0 0 0 2 0 0 0 9: 事业群1, C5.2, 主要, 未整改 3 0 1 1 1 0 0 0 3 0 0 0 8: 事业群2, C5.2, 关键, 延期 2023/1/1 0:00 3 0 1 1 1 0 0 0 3 0 0 0 4: 事业群2, C5.2, 一般, 关闭 2020/1/1 0:00 3 0 1 1 1 0 0 0 3 0 0 0 5: 事业群1, C5.2, 主要, 关闭 2020/1/1 0:00 3 0 1 1 1 0 0 0 3 0 0 0 6: 事业群2, C5.1, 关键, 未整改 3 0 1 1 1 0 0 0 3 0 0 0 2: 事业群2, B6.2, 一般, 关闭 2020/1/1 0:00 3 0 1 1 1 0 1 0 3 0 0 0 3: 事业群1, C5.1, 风险, 关闭 2020/1/1 0:00 3 0 1 1 1 0 1 0 3 0 0 0 1: 事业群1, A1.1, 风险, 延期 2023/1/1 0:00 3 0 1 1 1 0 1 1 3 0 0 1 -
可带标题行也可不带,但处理时要注意。
- 由于换行符的存在,一行不一定是表格中的一行。
- 常用于数据交换和存储。
变体
CSV 根据分隔符、换行方式、空内容表示方法、双引号表示方法、特殊字符处理方式等,可以分为多种变体。
常用的是 Excel 变体,格式如下:
- 以半角逗号分隔各列
- 如果内容有逗号或换行符,用半角双引号包裹
- 如果内容有半角双引号,则在前面的基础上双写内容中的半角双引号
- 一行的换行符为 CRLF(
\r\n)
如果以制表符为分隔符,也可以称作 TSV。
Excel 处理 CSV
Excel 变体的 CSV 文件可用 Excel 打开、编辑、储存。
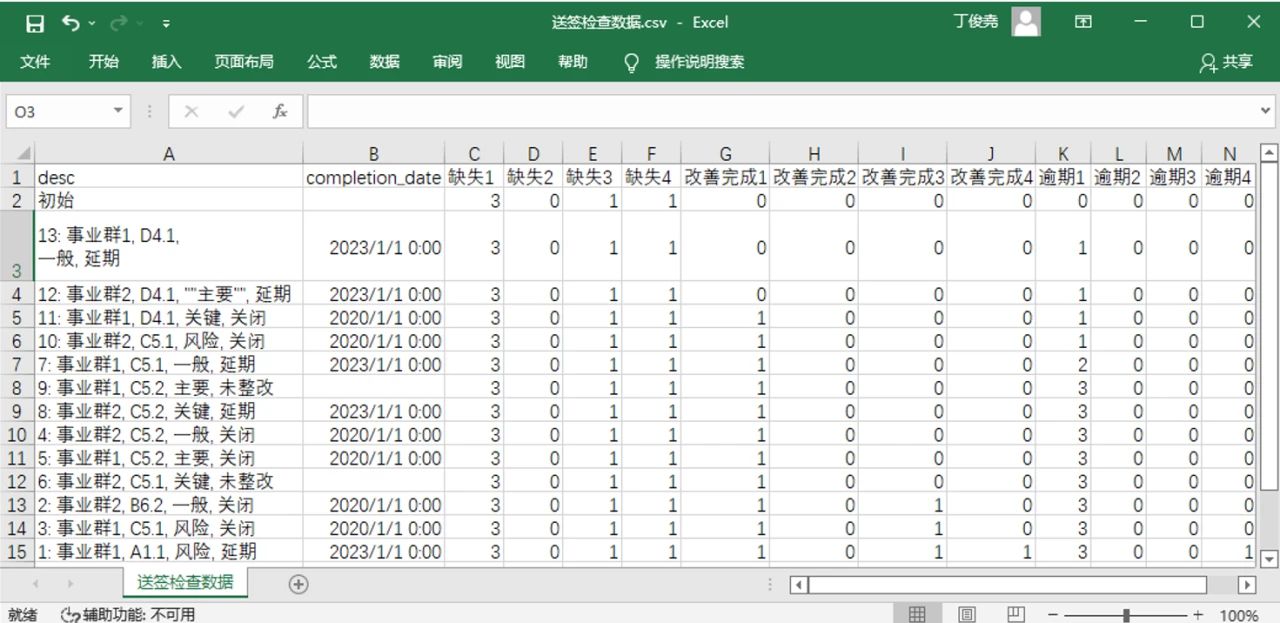
如果有小数,使用 Excel 打开后,精度可能有丢失。
保存时需要选择“CSV UTF-8”,而非“CSV”,否则会以系统默认编码(如 GBK、Big5)储存。
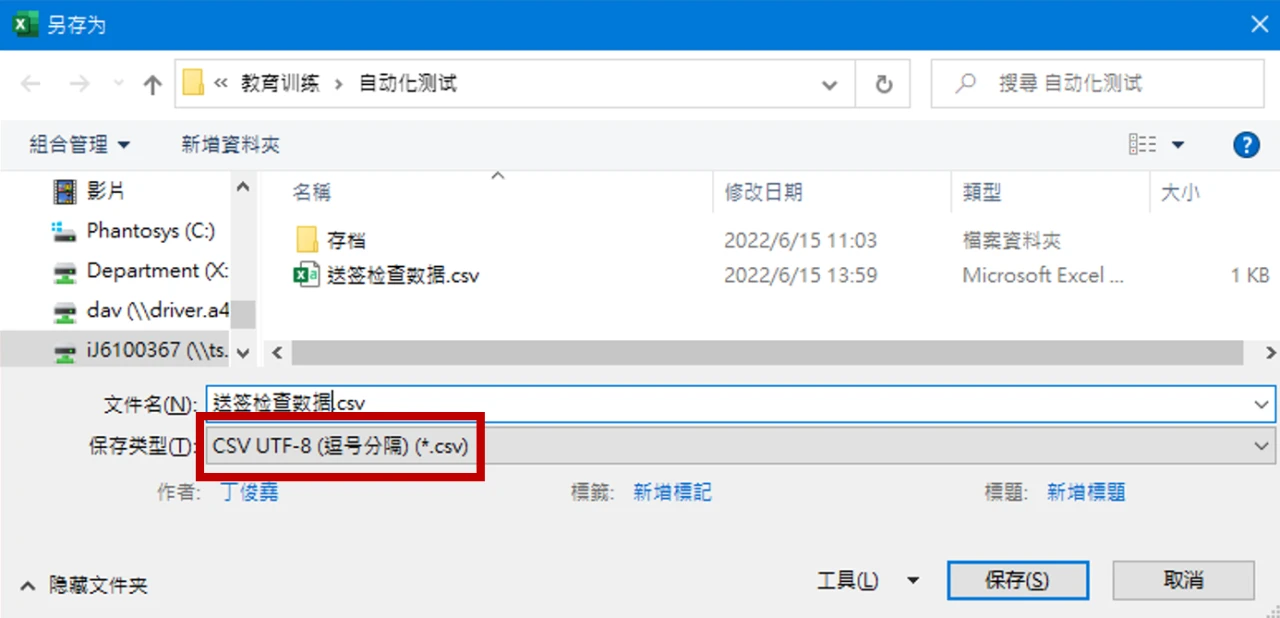
即便如此,存储格式实际上为 UTF-8 带 BOM 的格式,而许多程序默认的 UTF-8 编码不带 BOM,处理时会造成一些麻烦。
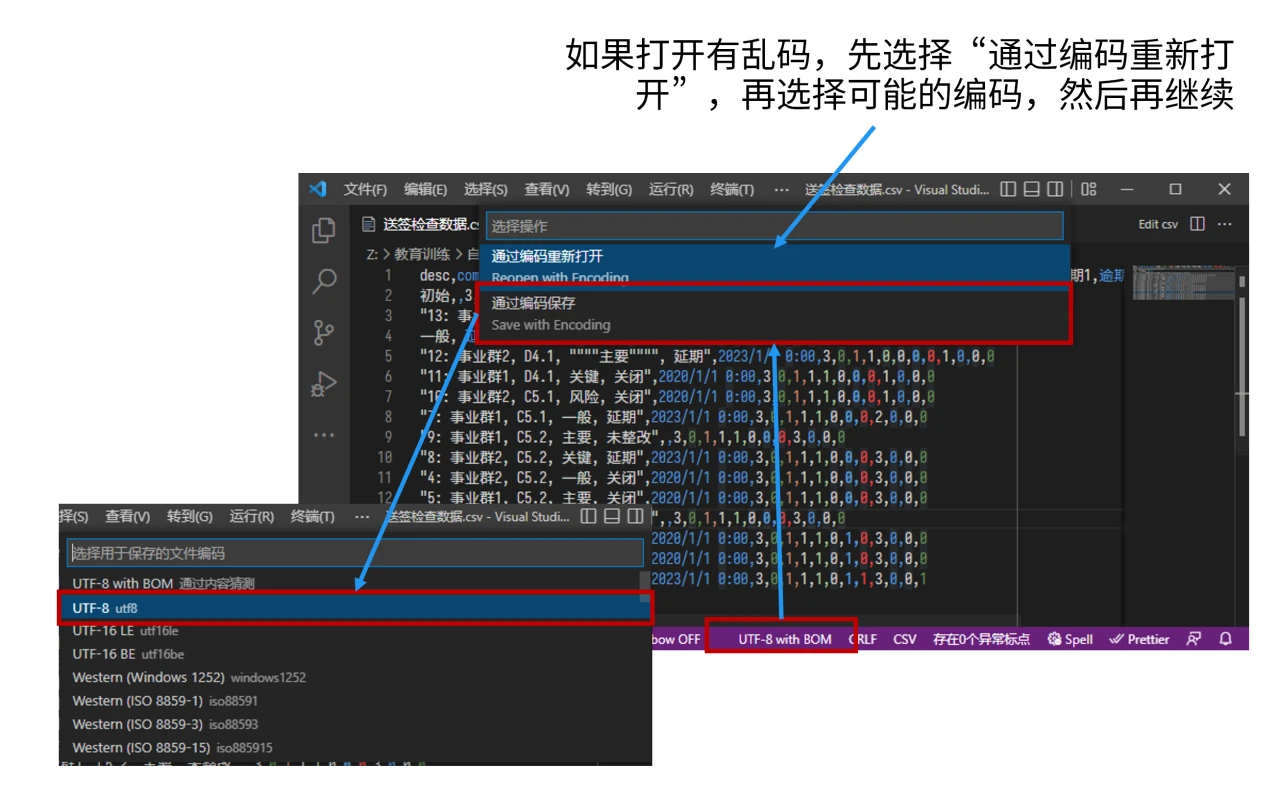
转换编码
大多数编辑器带此功能。以 Visual Studio Code 为例:
- 点状态栏的编码部分
- 如果打开的时候就有乱码,先选择“通过编码重新打开”,再选择可能的编码,如果正常,再继续
- 选择“通过编码保存”
- 选择需要存为的编码
Python 读 CSV
Python 有读写 CSV 的标准库 csv。
一种读取方式是用 reader 函数读取,结果是一个 _csv.reader 对象,其可迭代。迭代结果中,每一行为列表,其中每一项为字符串,表示该行各列的值。
这种读取方式不会考虑是否有表头,表头会被当做第一行。
另一种读取方式为创建 DictReader 类,可迭代。
迭代结果中,每一行为字典。键为第一行各列值,即表头;值为各列值。
这种读取方式,第一行为表头。
CSV 文件转为以 Python 字典格式为项目的列表(不考虑错误处理等情况):
Python 写 CSV
写 CSV 时,要确保打开文件时定义参数 newline='',否则每写一行都会多一个空行。
使用 write 函数创建一个对象 _csv.writer,用它的 writerow 和 writerows 方法写入行(前者为单行写入,后者为多行写入)。
写入行时,参数需可迭代。
Question
如果要更改 CSV 中某一行某一列的值,怎么做?
INI
initialization
格式示例
INI 是非正式标准,其变体非常多。
一般分若干节,每节有若干键值对,键和值之间用半角冒号或等号隔开,可用空格使文本美观。
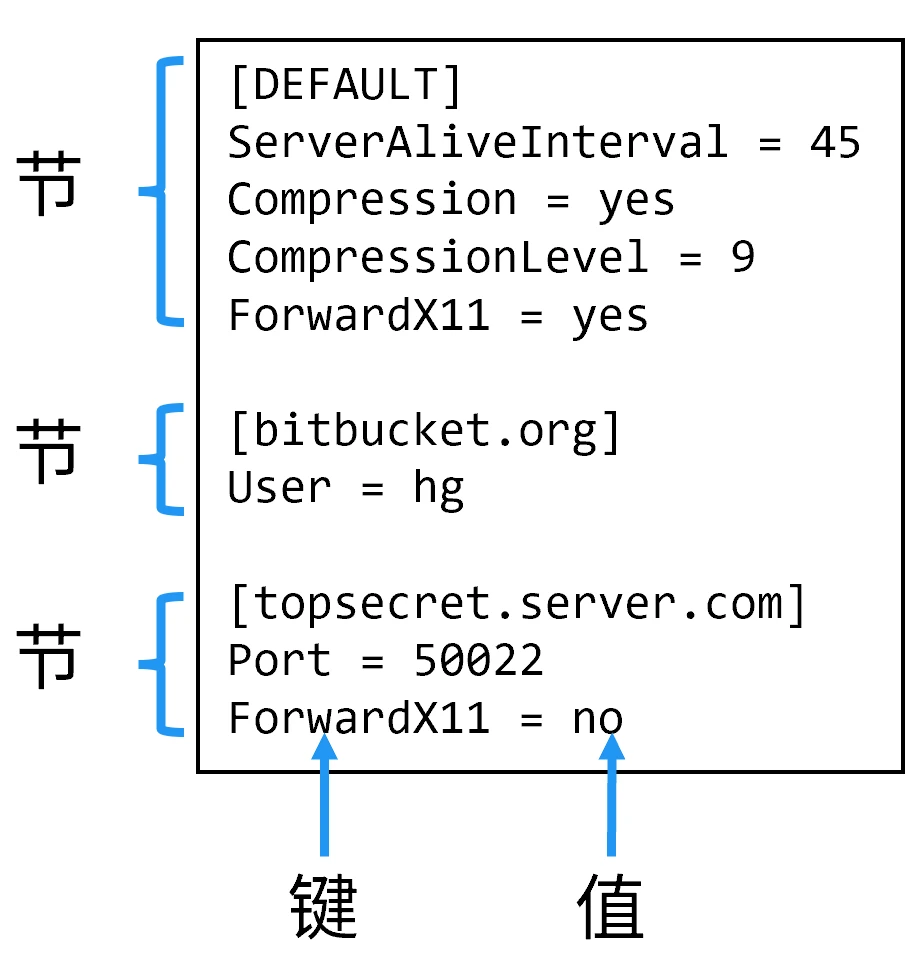
存储的是二维及以下的数据。
常用于记录配置(MySQL、PHP)。
Python 读 INI
使用标准库 configparser,使用其中的 ConfigParser 类实现读写。其尽可能为许多变体进行了适配。
节区分大小写,键不区分大小写。
DEFAULT 节可以配置各节的默认值。
任何情况下,值都被存储为字符串。
- 未定义的值存储为空字符串。
- 对于布尔值含义的文本,可以对节用
getboolean(键)方法转换为布尔值。 - 对于整数和浮点数,除直接转换外,也可以相应地用
getint()和getfloat()方法。
| ./test.ini | |
|---|---|
可以读多个配置,有冲突的键会被新的覆盖掉。
如果新读入默认配置,则会同步更改其他节的对应配置,但节内此前配置过的除外。
覆盖过程
| test.ini | |
|---|---|
-
初次从文件名读入
-
从字符串读入
-
从字典读入
-
再次从文件名读入
test2.ini
Python 写入 INI
用 ConfigParser 类的 write 方法写入。
传入文件对象,模式需为 w。
| test.ini | |
|---|---|
JSON
JavaScript Object Notation
格式示例
和 Python 的字典、字典组成的列表很像,不过引号必须是双引号。
可以不换行不缩进以缩减体积,也可以换行缩进以保证美观。
支持的数据类型:
- 字符串
- 数字
- 布尔值
- null
- 对象(用大括号包裹)
- 列表(用方括号包裹)
可以通过嵌套表达多维的数据。
常用于数据交换,也可用于记录配置(Docker)。
Python 将其他数据类型转为 JSON
Python 有标准库 json 以读写 JSON 字符串。
使用 json.dumps(字典或列表) 转为字符串。
使用 json.dump(字典或列表, 文件对象) 转到文件。
Python 将 JSON 转为其他数据类型
使用 json.loads() 从字符串转。
使用 json.load() 从 IO(包括文件对象)转。
| test.json | |
|---|---|
YAML
YAML Ain't Markup Language
格式示例
依靠缩进表达层级(嵌套)关系,一般是两个空格。
列表各项可以以 - 加上空格开头。
可以写注释。
可以用 --- 分段,将多个文档写到一个文件中。
常用于记录配置(Docker Compose)。
Python 将其他数据类型转为 YAML
需要安装第三方模块,如 PyYAML。
直接写入文件:
将多条数据转为 YAML 字符串(这时字符串会包含多段;也可以转为文件):
| test2.yml | |
|---|---|
Python 将单段 YAML 转为其他数据类型
可以用 yaml.load() 处理,但要传入 Loader 参数。也可以直接使用 yaml.safe_load()。
可以传入文件对象。
Python 将多段 YAML 转为其他数据类型
可以用 yaml.load_all() 处理,但要传入 Loader 参数。也可以直接使用 yaml.safe_load_all()。
可以传入文件对象。
TOML
Tom 的(语义)明显、(配置)最小化的语言(Tom's Obvious, Minimal Language)
格式示例
样式很像 INI,但支持的功能更多。
不允许不写值。
详细的语法:https://toml.io/cn/v1.0.0。
常用于记录配置。
Python 将 TOML 转为字典
Info
新版的 Python 有处理 TOML 的标准库,编写该教程的时候,还没有。
以 pytomlpp 库为例:
从字符串读可以使用 pytomlpp.loads():
从文件读可以用 pytomlpp.load(),传入文件对象:
Python 将字典转为 TOML
转为字符串用 pytomlpp.dumps(字典);转为文件用 pytomlpp.dump(字典, 文件对象)。
XML
可扩展标记语言(EXtensible Markup Language)
格式示例
与 HTML 类似,不过可以自定义标签名、属性等。
以前常用于数据交换,现在也用于记录配置(Maven)。
Python 解析 XML
Python 标准库提供有 xml,用于解析 XML,但如果 XML 有恶意代码,可能会存在安全问题。Python 官方文档推荐使用第三方的 defusedxml 模块替代,以提高安全性。
XML 的解析可以使用 DOM、SAX 和 ElementTree API 三种方法,这里只介绍 ElementTree API 的简单的方法。
使用 defusedxml.ElementTree.parse() 解析:
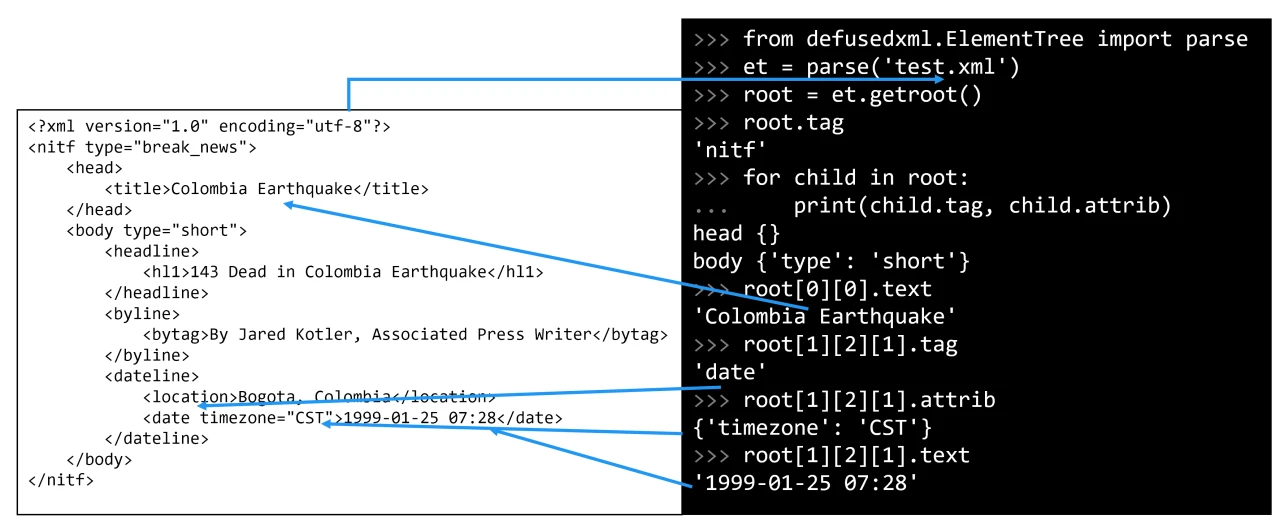
使用 defusedxml.ElementTree.parse(文件路径或文件对象) 解析为 ElementTree 对象,再对其使用 getroot() 方法获得 Element 对象。
使用 defusedxml.ElementTree.fromstring(字符串) 解析为 Element 对象。
对 Element 对象使用 find(XPath) 方法,返回第一个符合条件的对象。
使用 findall(XPath) 方法,返回所有符合条件的对象组成的列表。
使用 iter(标签名) 方法,可以生成一个生成器,可迭代所有为这个标签名的对象。
Python 写入 XML
可以对 ElementTree、Element 对象进行新增、修改、删除等操作。
一些操作需要 xml 模块下的包。
使用 xmltodict 实现 XML 与字典互换
xmltodict 是第三方模块。
xmltodict.parse(字符串或文件对象) 可以将 XML 转换为字典。
- 如果传入文件对象,需确保以二进制形式打开。
- 默认情况下,如果有参数,则会成为标签下的键,键为
@加上参数名;这种情况下,如果有文本,则会成为标签下的键,键为#text。
xmltodict.unparse(字典) 可以将字典转换为 XML。对字典格式有要求。
总结

| 文件格式 | CSV | INI | JSON | YAML | TOML | XML |
|---|---|---|---|---|---|---|
| 使用的模块 | csv |
configparser |
json |
yaml |
pytomlpp |
xml; defusedxml |
| 是否是标准库 | 是 | 是 | 是 | 否 | 否 | 是;否 |
| 从数据读 | .ConfigParser() > .read_string(字符串) 或 .read_dict(字典) |
.loads(字符串) → 字典、列表等 |
.safe_load(字符串) → 字典、列表等 |
.loads(字符串) → 字典 |
.ElementTree.fromstring(字符串) → Element |
|
| 从文件读(里面的“流”可以用文件对象指代) | .reader(流) 或 .DictReader(流) |
.ConfigParser() > .read(文件名) |
.loads(流) → 字典、列表等 |
.safe_load(流) → 字典、列表等 |
.load(流) → 字典 |
.ElementTree.parse(文件路径或流) → ElementTree |
| 写到数据 | .dumps(字典或列表, ...) → 字符串 |
.dump(字典或列表, ...) → 字符串 |
.dumps(字典) → 字符串 |
xml.etree.ElementTree.dump() → 字符串 |
||
| 写到文件(里面的“流”可以用文件对象指代) | .writer(流) > .writerow(一行的列表) 或 .writerows(包含各行的列表) |
.ConfigParser() > .write(流) |
.dump(字典或列表,流, ...) |
.dump(字典或列表,流, ...) |
.dump(字典, 流) |
.ElementTree.parse() > .write(文件路径或流) |
参考资料
- Python操作CSV格式文件的方法大全_python_脚本之家
- csv --- CSV 文件读写 — Python 3.10.5 文档
- configparser --- 配置文件解析器 — Python 3.10.5 文档
- RFC 7159 - The JavaScript Object Notation (JSON) Data Interchange Format
- The Official YAML Web Site
- python yaml用法详解_EastonLiu的博客-CSDN博客_python yaml
- yaml/pyyaml: Canonical source repository for PyYAML
- toml-lang/toml: Tom's Obvious, Minimal Language
- TOML: 简体中文 v1.0.0
- 现实生活中的 XML
- XML处理模块 — Python 3.10.5 文档
- defusedxml · PyPI
- xml.etree.ElementTree --- ElementTree XML API — Python 3.10.5 文档