HTTP 请求
约 2837 个字 102 行代码 5 张图片 预计阅读时间 11 分钟
报文结构
基于浏览器的基础的 HTTP 请求报文示例,操作:浏览器访问 http://httpbin.org/get
每行以 CRLF 换行,最后有一空行后面也有 CRLF。
各部分说明:
Info
并非所有部分必要。需要根据服务端情况给定需要的参数。
-
首行为请求行。对于上例,各部分含义:
GET:请求用的方法/get:URL。一般是省略协议和主机的,不过用完整的也行。HTTP/1.1:HTTP 协议版本
Info
之后每行包含首部的字段名和值:
字段名: 值 -
Accept:能够接受的文件类型,用 MIME 表示 Accept-Encoding:一般指用户端能够使用的压缩方式,服务器可据此对内容压缩,便于传输Accept-Language:用户希望优先得到的语言Cache-Control:值设置为no-cache,表示在发布缓存副本之前,强制要求缓存把请求提交给原始服务器进行验证(协商缓存验证)DNT:值设置为1,表示用户不愿意目标站点追踪用户个人信息Host:请求的主机,如自定义端口号也写在这里Pragma:值设置为no-cache,与Cache-Control: no-cache效果一致(已弃用)Proxy-Connection:服务器发送完响应报文后请保持连接Upgrade-Insecure-Requests:用户端支持 upgrade-insecure-requests 的升级机制- upgrade-insecure-requests:指示客户端将该站点的所有不安全 URL(通过 HTTP 提供的 URL)视为已被替换为安全 URL(通过 HTTPS 提供的 URL)。该指令适用于需要重写大量不安全的旧版 URL 的网站。
User-Agent:用户代理(UA),一般表示浏览器信息
URL 与 URI
URL
统一资源定位器(Uniform Resource Locator)
指定在 Internet 上可以找到资源的位置的文本字符串,表示给定的独特资源在 Web 上的地址。
在 HTTP 的上下文中,URL 被叫做“网络地址”或“链接”。你的浏览器在其地址栏显示 URL,例如 https://developer.mozilla.org
URL 也可用于文件传输(FTP),电子邮件(SMTP)和其他应用。
URI
统一资源标识符(Uniform Resource Identifier)
是一个指向资源的字符串,最通常用在 URL 上来指定 Web 上资源文件的具体位置。
相比之下,URN 是在给定的命名空间用名字指向具体的资源,如:书本的 ISBN。
区别和关系
-
URI 是相对的,需要有参考系。
如
http://a.com/b/c/d.html,其中:d.html对于c、http://a.com/b/c而言是 URIc/d.html对于b、http://a.com/b而言是 URI/b/c/d.html对于http://a.com/而言是 URI
-
URL 是 URI 的子级(是级别上的子级,是继承关系,不是包含)。
- URL 一般是一个完整的链接,而 URI 往往不是。
MIME 类型
媒体类型(MIME 类型,Multipurpose Internet Mail Extensions)是一种标准,用来表示文档、文件或字节流的性质和格式,由 IANA 管理。
语法结构:类型/子类型
类型分为两种:
- 独立类型:表明对文件的分类(见下)
- Multipart 类型:
multipart/form-data:多部分文档格式,用于 HTTP 表单multipart/byteranges:把部分的响应报文发送回浏览器
独立类型的分类和示例:
| 类型 | 描述 | 典型示例 |
|---|---|---|
text |
表明文件是普通文本,理论上是人类可读 | text/plain, text/html, text/css, text/javascript |
image |
表明是某种图像。不包括视频,但是动态图(比如动态 gif)也使用 image 类型 |
image/gif, image/png, image/jpeg, image/bmp, image/webp, image/x-icon, image/vnd.microsoft.icon |
audio |
表明是某种音频文件 | audio/midi, audio/mpeg, audio/webm, audio/ogg, audio/wav |
video |
表明是某种视频文件 | video/webm, video/ogg |
application |
表明是某种二进制数据 | application/octet-stream, application/pkcs12, application/vnd.mspowerpoint, application/xhtml+xml, application/xml, application/pdf |
用户代理
UA(User Agent)
服务器可以根据用户代理字符串,判断用户使用什么浏览器访问网页,如:
- 判断浏览器及其版本是否兼容网站
- 判断是否在某程序下运行(如微信)
- 判断系统和版本,提供对应系统的下载链接
服务器也可以据此判断来源是否为搜索引擎爬虫。如一些动态网站,可以给爬虫和普通用户提供两种内容,前者可能利于 SEO 和搜索引擎的收录。
许多网站提供检查用户 UA、判断浏览器和系统环境的功能。
浏览器的“请求桌面网站”之类的功能,很大程度上就是更改 UA。
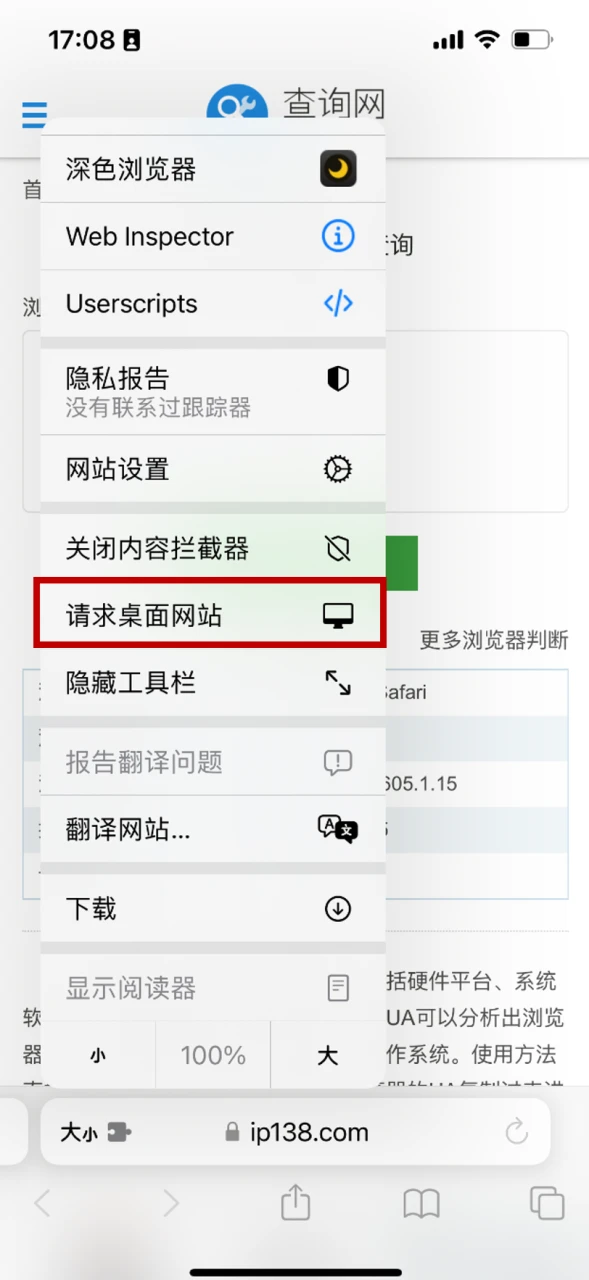
常见的用户代理字符串举例
Microsoft Edge(基于 Chromium) 102.0.1245.44, Windows 11 企业版 21H2:
Google Chrome 102.0.5005.115, Windows 11 企业版 21H2:
Microsoft Internet Explorer 11.0.22000.120, Windows 11 企业版 21H2(通过执行 hh http://httpbin.org/get 获取):
Apple Safari, iOS 15.5, iPhone 13 Pro, MLTE3CH/A:
微信 8.0.23, Apple Safari, iOS 15.5, iPhone 13 Pro, MLTE3CH/A, 使用 WiFi,系统语言为简体中文:
在浏览器中自定义 UA 字符串
以 Edge 为例(Chromium 内核的都可以这么做):
- 打开开发人员工具,点加号
- 点“网络条件”
- 在其中的“用户代理”中,取消勾选“用户浏览器默认”
- 此时可自定义用户代理:可以选择列表中的,也可以自己填写,甚至可以通过填写设备信息来自定义 UA
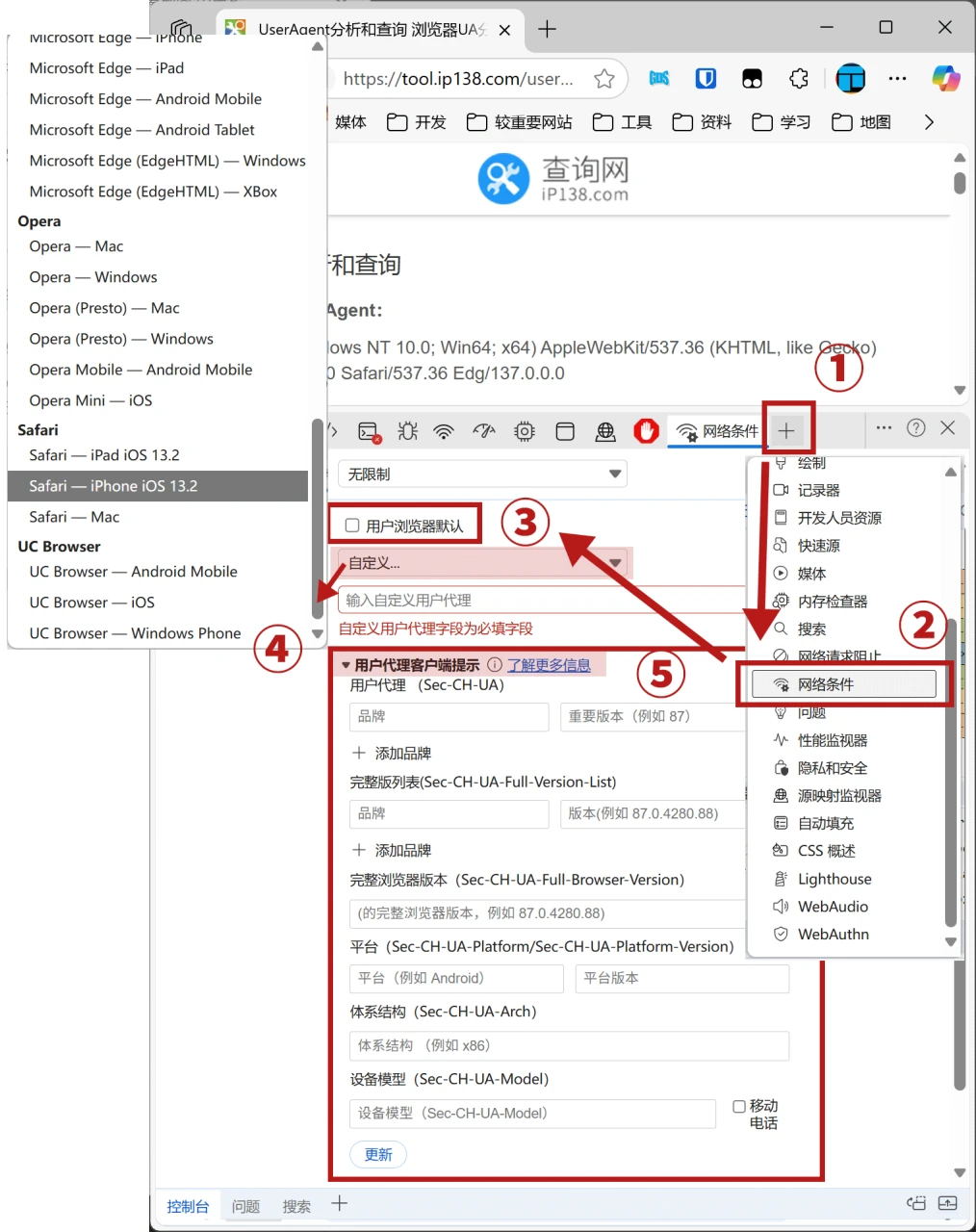
在桌面端浏览器上尽可能模拟其他设备
以 Edge 为例(Chromium 内核的都可以这么做):
- 打开开发人员工具,点“自定义”按钮,
- 点“设备仿真”
- 在浏览器界面上方的“尺寸”中选择设备型号
- 右边还可以自定义尺寸、缩放、网络环境、旋转等
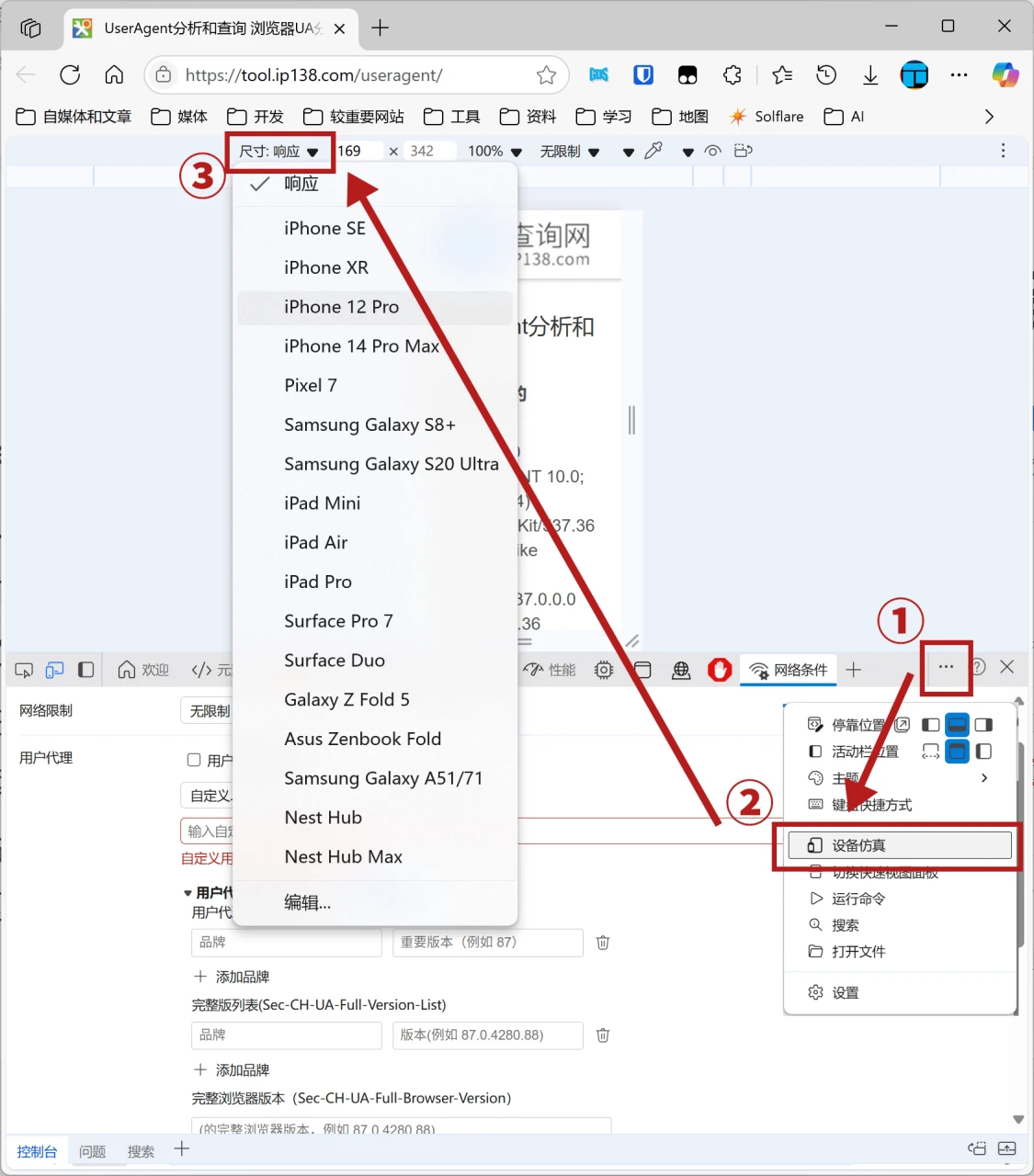
HTTP 版本
- 0.9:最初版本,仅支持 GET,仅能访问 HTML
- 1.0:基础的 HTTP 版本,默认单次请求前后都会进行 TCP 建立、断开连接
- 1.1:
- 支持持久连接:默认请求后不会立即关闭连接,通过请求头的 Connection 参数,控制连接的断开。在多次请求时,不会断开连接,以减少 TCP 握手的时间;
- 支持断点续传:通过 RANGE 参数告知该从哪传输
- 1.1:
- 2:
- 支持多路复用:允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息
- 二进制分帧
- 首部压缩
- 服务端推送
URL 编解码
URL 编码
URL 中一般只能使用 ASCII 字符,且有一些符号有特殊含义。遇到特殊符号或非 ASCII 字符,需要进行 URL 编码。
URL 编码一般会根据 UTF-8 编码转换。对于需编码的字符,将对应的字符换为 % 加上字符的 UTF-8 16 进制编码。
对于 ASCII 定义的字符,其 UTF-8 16 进制编码和 ASCII 16 进制编码一样。
例:
其中:
| 字符 | UTF-8 的 16 进制编码(按字节分隔) | 备注 |
|---|---|---|
α |
CE B1 |
|
/ |
2F |
|
β |
CE B2 |
|
测 |
E6 B5 8B |
|
试 |
E8 AF 95 |
|
|
20 |
空格 |
A |
41 |
无需额外编码 |
B |
42 |
无需额外编码 |
测 |
E6 B5 8B |
|
试 |
E8 AF 95 |
|
1 |
31 |
无需额外编码 |
故结果为:
Info
查看各字符的 UTF-8 编码可以参考 https://symbl.cc/
URL 编码的解码
接上例。
-
将 URL 编码的
%XX部分转换为二进制:%CE%B1%2F%CE%B2%E6%B5%8B%E8%AF%95%20AB%E6%B5%8B%E8%AF%95111001110 101100011 00101111 11001110 10110010 11100110 10110101 10001011 11101000 10101111 10010101 00100000 A B 11100110 10110101 10001011 11101000 10101111 10010101 1 -
根据下表的信息划分字符,以及各字符的非固定部分
Unicode 编码(16进制) UTF-8 字节流(二进制) 单个字符对应字节数 000000-00007F0XXXXXXX1 000080-0007FF110XXXXX 10XXXXXX2 000800-00FFFF1110XXXX 10XXXXXX 10XXXXXX3 010000-10FFFF11110XXX 10XXXXXX 10XXXXXX 10XXXXXX4 划分结果:
11001110 10110001 00101111 11001110 10110010 11100110 10110101 10001011 11101000 10101111 10010101 00100000 A B 11100110 10110101 10001011 11101000 10101111 10010101 1 -
将各字符的非固定部分的二进制数字去除前导零,转换为 16 进制;转换后不足 4 位的加上前导零到 4 位(一般 Unicode 编码都是 4 位起步)
01110110001 0101111 01110110010 0110110101001011 1000101111010101 0100000 A B 0110110101001011 1000101111010101 11110110001 101111 1110110010 110110101001011 1000101111010101 100000 A B 110110101001011 1000101111010101 13B1 2F 3B2 6D4B 8BD5 20 A B 6D4B 8BD5 103B1 002F 03B2 6D4B 8BD5 0020 A B 6D4B 8BD5 1 -
查 Unicode 表,找到对应的字符:
Info
根据 Unicode 编码找字符,依然可以参考 https://symbl.cc/
Info
许多网站提供 URL 编解码的功能。
HTTP 请求方法
请求方法的含义只是推荐含义,实际使用没有太多限制,由开发者决定如何使用。
GET:请求信息POST:向服务器发送信息PUT、DELETE:目前多用在 RESTful API 中,意为添加、删除某项内容(相对应的,POST一般意为更改某项内容),用法和POST差不多OPTION、HEAD、TRACE、CONNECT:不常用,分别意为请求选项、首部、环回测试、代理服务器- 现在
OPTIONS常用于预检,在产生跨域请求时先向服务器发起预检,服务器接受跨域请求后才会处理
- 现在
GET 请求
一般使用浏览器输入 URL 访问网址,实质上进行了 GET 请求。
GET 请求可以带参数,参数(parameter)放在 URL(路径) 中:
上例中有三个参数,参数与原路径间用 ? 隔开,每个参数之间用 & 隔开:
- 参数名
param1,值1 - 参数名
param2,值hello - 参数名
param3,该值使用 URL 编码形式储存,编码后值为%E6%B5%8B%E8%AF%95。
根据上面的 URL 编码规则,可以得出 param3 的值解码为 测试。
特点
- 参数在 URL 中明文表示,通过浏览器历史记录就能够回溯,复制链接、存放到收藏夹 / 书签,均可以在此后执行同样的请求
- 可能会缓存数据(视浏览器配置、服务器配置而定)
- 浏览器和服务器都会对 URL 长度进行限制,故 GET 请求的参数过长时,会导致错误;故 GET 请求不能放置过长的参数
POST 请求
一般不能通过在地址栏访问 URL 实现,而是调用程序实现。
能够传输更多内容。
附带数据的请求
POST 请求的参数一般放在请求主体中,而非路径(放在路径也行,也能读取,但就失去了使用 POST 的意义了);这时候一般叫做数据(data)。
其写法类似于 GET 中的参数,同样需要 URL 编码。
附带表单的请求
如果首部附加上表示请求类型的字段,如下:
表明请求主体是一个表单(form):
附带文件的请求
如果首部附加上表示请求类型的字段,如下:
表明请求主体是表单,且里面有文件(file)。
其中 boundary (定界符)的值不固定,用于分隔各字段,可以在构建请求时自动随机生成。
这种请求中,请求体中的每一项格式如下(末尾均有 CRLF):
| 文件 | |
|---|---|
实际上,针对文件,还可以另外添加字段:
示例
本例中有 3 个普通表单字段、2 个文件表单字段,其中一个是 JPEG 文件,另一个是 PNG 文件。
请求体采用二进制传输,不需要进行 URL 编码。
定界符为 testboundary。
特点
- 数据在请求实体中,而非 URL 中,这样不会在 URL 中明文显示,查询历史记录一般也无法查到传输的数据,更加安全
- 请求主体仍然可以被抓包软件等监听
- 因为数据不依赖 URL 传输,故能够传输更大的数据(但不是无限大,受用户、服务器限制)
- 无法通过收藏夹 / 书签复现;如果通过浏览器实现 POST 请求并重定向,如果要返回上一页,则会有警告:
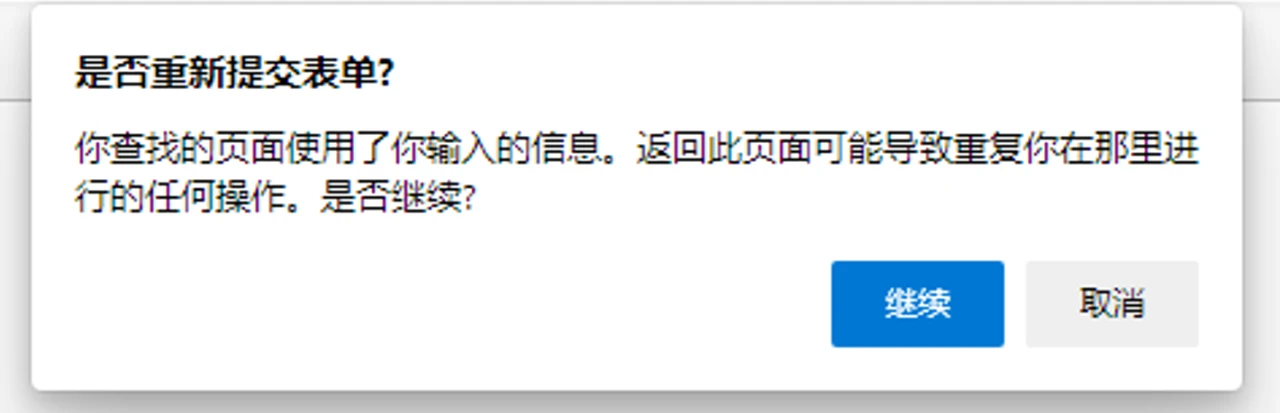
- 不会缓存数据