Pandas 基础
约 2066 个字 180 行代码 5 张图片 预计阅读时间 9 分钟
引入
为什么用 Pandas?
- 一些数据不在数据库中,而是分布于文件、字符串中。
- 一些情况下希望在本地处理数据,而非依赖数据库。
- 对数据精度有要求。
- 如果采用循环的方式处理数据,效率较低,而数据处理中,经常需要大范围计算数据。
Pandas 底层依赖于 NumPy 和 Cython。
- NumPy 是矩阵计算相关的模块,底层使用 C 语言,在批量计算数据时,速度明显快于使用纯 Python 进行循环计算。
- Cython 简单来说是一种编译器,可以借此编写 Python 的 C 语言扩展,提高执行速度。
一些模块对此有支持:
如 Jupyter,可以美化输出 Pandas 的表数据,常用于数据、计算与人工智能的演算,可以当作演算工具使用。VS Code 可以通过插件支持 Jupyter。
在 VS Code 中使用 Jupyter
- 安装 Jupyter 扩展(运行时也会调用
pip安装需要的模块) -
按 ++Ctrl+Shift+P++,调出命令窗口,输入或找到“Jupyter: 创建交互式窗口”,点击或按回车,即可进入交互式窗口

执行命令
在这个窗口,可以输入代码并运行,且能够直接查看结果。
输入的代码或结果可以保存为 ipynb 文件(Jupyter Notebook),后续可以查看、执行、修改。
直接创建 ipynb 文件也可以。
导入模块
pd 是习惯的、约定俗成的缩写。接下来都会简称为 pd。
同理,与其高度相关的 NumPy 模块也有约定俗成的简称:
一些基本概念
Series:一维数据,可理解为表的一列。
DataFrame:二维数据,可理解为表。可以看做有列名的多个 Series 的集合。
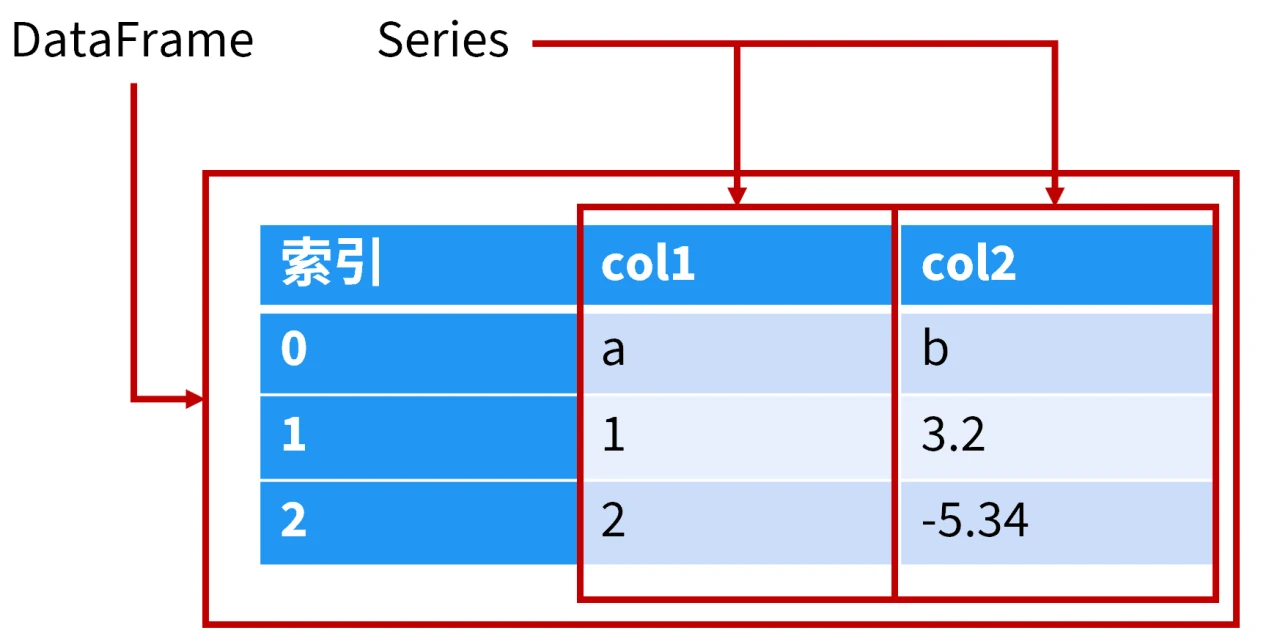
构建一维数据
pd.core.series.Series
一个 Series 可以分为四部分:
data:序列的值(绝大多数情况下填这个即可)index:索引(默认会有一个从0开始的索引)dtype:存储类型name:序列名称
例
类比为:
引用名:s;Series 名:my_name
| 索引 (索引名 my_idx) |
值 (类型为 object) |
|---|---|
| id1 | 100 |
| 20 | a |
| third | {'dic1': 5} |
不同数据类型
整数
数据类型:np.int64
浮点数
数据类型:np.float64
字符串
数据类型:str
空实例
| 上面 Series 输出 | |
|---|---|
空值处理
如果数据中有 None 等空值,则会视其他元素的类型,变为 NaN(Not a Number,仍然为 np.float* 类型)或 None:
变为 NaN
数据类型:np.float64
变为 None
三列的数据类型分别为:str、NoneType、float。
一维数据的属性
以“构建一维数据 > 例”中的 s 为例。
| 属性名 | 含义 | 例子中该属性的值 |
|---|---|---|
values |
值 | array([100, 'a', {'dic1': 5}], dtype=object) |
index |
索引 | Index(['id1', 20, 'third'], dtype='object', name='my_idx') |
dtype |
存储类型 | dtype('O') |
name |
名称 | 'my_name' |
shape |
返回只有一个整数的元组,这个整数表示长度 | (3,) |
empty |
是否为空 | False |
遍历数据
Series 对象本身可迭代,但是迭代过程中可能会转换数据类型。如不想转换,可使用其 values 属性迭代。
数据类型为 np.int64。
取一维数据单个索引的值
以“构建一维数据 > 例”中的 s 为例。
像字典一样取值:
如果索引非数字开头,可以用属性的方式取值:
构建二维数据
pandas.core.frame.DataFrame
columns:表示各列列名。
例
例 1
类比为:
| col_0 | col_1 | col_2 | |
|---|---|---|---|
| row_0 | 1 | a | 1.2 |
| row_1 | 2 | b | 2.2 |
| row_2 | 3 | c | 3.2 |
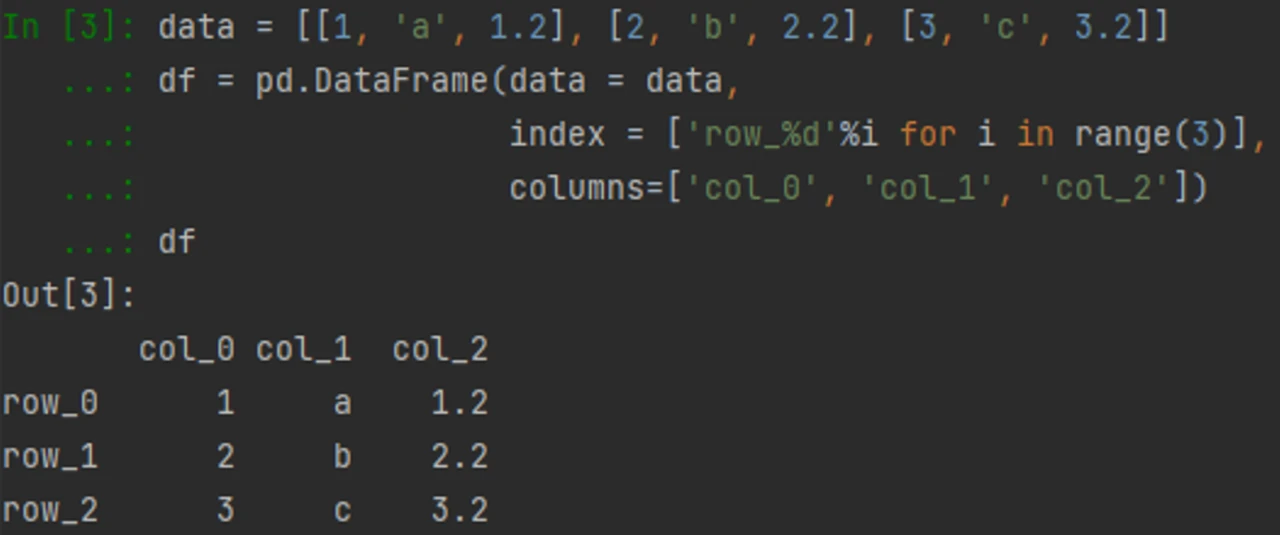
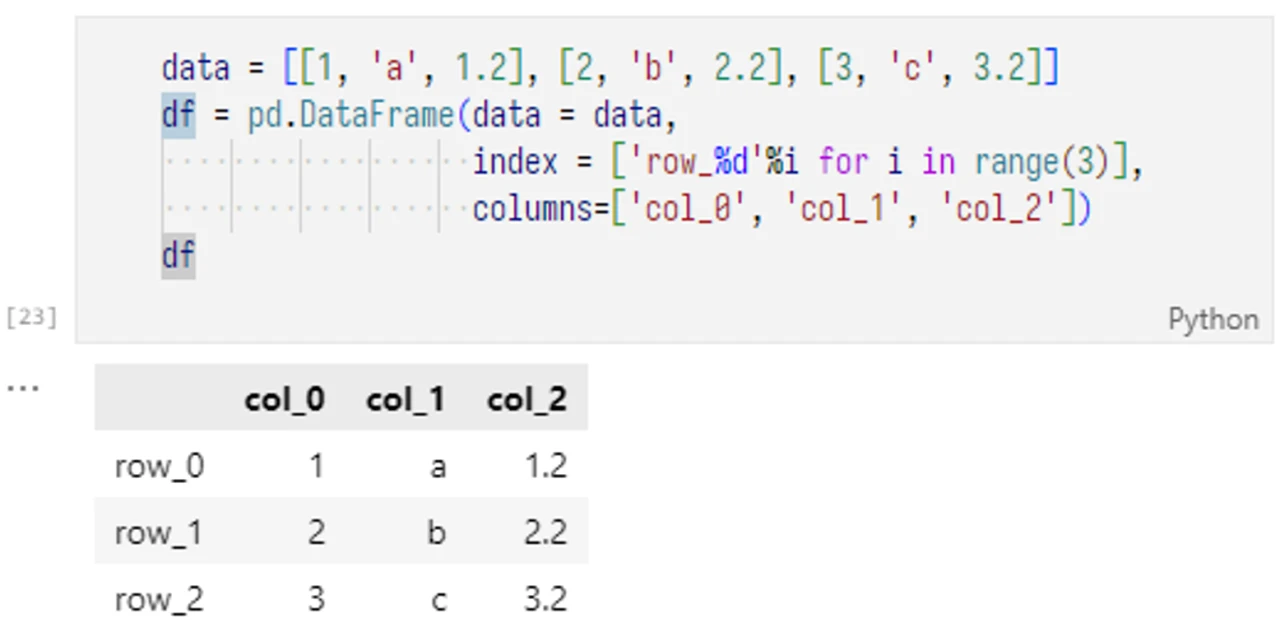
例 2
data 如果是列表等可迭代对象,则其中的子元素除了列表等可迭代对象外,还可以是字典,表示一行。键表示列名,值表示该行对应列的值。
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 1 | 2 | 3 | NaN |
| 1 | 2 | 5 | NaN | NaN |
| 2 | NaN | NaN | 34 | 3 |
例 3
data 可以填多种形式的内容,除了列表等可迭代对象外,还可以是字典。如果 data 是字典,则每一个键值对代表列名、各列的值:
| s | col_0 | col_1 | col_2 |
|---|---|---|---|
| row_0 | 1 | a | 1.2 |
| row_1 | 2 | b | 2.2 |
| row_2 | 3 | c | 3.2 |
二维数据的切片
以“构建二维数据 > 例 > 例 3”里面的 df 为例:
如果取其中一列,使用 df[列名] 的形式,得到 Series:
如果取若干列,使用 df[[列名1, 列名2, ...]] 的形式,得到 DataFrame:
| col_0 | col_1 | |
|---|---|---|
| row_0 | 1 | a |
| row_1 | 2 | b |
| row_2 | 3 | c |
实际上,可以使用 df[条件表达式] 的方式来进行数据的筛选。条件表达式的结果为真的数据会被筛选出来:
上例得到一个 DataFrame:
| s | col_0 | col_1 | col_2 |
|---|---|---|---|
| row_1 | 2 | b | 2.2 |
| row_2 | 3 | c | 3.2 |
二维数据的转置
以“构建二维数据 > 例 > 例 3”里面的 df 为例:
| s | row_0 | row_1 | row_2 |
|---|---|---|---|
| col_0 | 1 | 2 | 3 |
| col_1 | a | b | c |
| col_2 | 1.2 | 2.2 | 3.2 |
二维数据的属性
以“构建二维数据 > 例 > 例 3”里面的 df 为例:
| 属性名 | 含义 | 例子中该属性的值 |
|---|---|---|
| values | 值 | |
| index | 行索引 | Index(['row_0', 'row_1', 'row_2'], dtype='object') |
| columns | 列索引 | Index(['col_0', 'col_1', 'col_2'], dtype='object') |
| dtypes | 存储类型,返回 Series |
|
| shape | 返回有两个整数的元组,分别表示行数和列数 | (3, 3) |
| empty | 是否为空 | False |
练习
- 如果我想取某个
DataFrame(称为df)的前n列,但我不知道它的列名,如何处理? - 如果是前
n行呢?
读入、导出数据
读入数据
读入数据的方法:pd.read_*(数据路径等),参数大同小异。
一些方法需要第三方模块(如读 Excel 需要 xlrd、xlwt、openpyxl)。
返回 DataFrame 对象。
有哪些方法?
| 可用的方法 | |
|---|---|
例
| test.csv | |
|---|---|
| 1 | col1 | col2 | col3 | col4 | col5 |
|---|---|---|---|---|---|
| 0 | 2 | a | 1.4 | apple | 2020/1/1 |
| 1 | 3 | b | 3.4 | banana | 2020/1/2 |
| 2 | 6 | c | 2.5 | orange | 2020/1/5 |
| 3 | 5 | d | 3.2 | lemon | 2020/1/7 |
经过上面的处理,col5 列数据类型为 np.datetime64。
导出数据
导出数据的方法:pd.to_*(要导出的路径等)
有哪些方法?
| 可用的方法 | |
|---|---|
数据的计算
示例数据:
| School | Grade | Name | Gender | Height | Weight | Transfer | Test_Number | Test_Date | Time_Record | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Shanghai Jiao Tong University | Freshman | Gaopeng Yang | Female | 158.9 | 46 | N | 1 | 2019/10/5 | 0:04:34 |
| 1 | Peking University | Freshman | Changqiang You | Male | 166.5 | 70 | N | 1 | 2019/9/4 | 0:04:20 |
| 2 | Shanghai Jiao Tong University | Senior | Mei Sun | Male | 188.9 | 89 | N | 2 | 2019/9/12 | 0:05:22 |
| 3 | Fudan University | Sophomore | Xiaojuan Sun | Female | NaN | 41 | N | 2 | 2020/1/3 | 0:04:08 |
| 4 | Fudan University | Sophomore | Gaojuan You | Male | 174 | 74 | N | 2 | 2019/11/6 | 0:05:22 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 195 | Fudan University | Junior | Xiaojuan Sun | Female | 153.9 | 46 | N | 2 | 2019/10/17 | 0:04:31 |
| 196 | Tsinghua University | Senior | Li Zhao | Female | 160.9 | 50 | N | 3 | 2019/9/22 | 0:04:03 |
| 197 | Shanghai Jiao Tong University | Senior | Chengqiang Chu | Female | 153.9 | 45 | N | 1 | 2020/1/5 | 0:04:48 |
| 198 | Shanghai Jiao Tong University | Senior | Chengmei Shen | Male | 175.3 | 71 | N | 2 | 2020/1/7 | 0:04:58 |
| 199 | Tsinghua University | Sophomore | Chunpeng Lv | Male | 155.7 | 51 | N | 1 | 2019/11/6 | 0:05:05 |
运算
可以使用一般的运算符,实际效果是操作给定的所有数据。
| Height | Weight | |
|---|---|---|
| 0 | 158.9 | 46 |
| 1 | 166.5 | 70 |
| 2 | 188.9 | 89 |
| 3 | NaN | 41 |
| ... | ... | ... |
| 198 | 175.3 | 71 |
| 199 | 155.7 | 51 |
| 1 | Height | Weight |
|---|---|---|
| 0 | 157.9 | 45 |
| 1 | 165.5 | 69 |
| 2 | 187.9 | 88 |
| 3 | NaN | 40 |
| ... | ... | ... |
| 198 | 174.3 | 70 |
| 199 | 154.7 | 50 |
统计
对 Series 和 DataFrame 均可使用以下方法:
- 总计:
sum() - 均值:
mean() - 中位数:
median() - 样本方差:
var() - 样本标准差:
std() - 最大值:
max() - 最小值:
min() n(0~1)分位数处的值:quantile(n)- 非缺失值个数:
count() - 最值所在索引:
idxmax()、idxmin()
对 DataFrame 使用,返回一个 Series;对 Series 使用,返回一个值。
| 统计 DataFrame | |
|---|---|
| 统计 Series | |
|---|---|
| 上例计算结果 | |
|---|---|
去重
Series 有以下与去重相关的方法:
-
unique():返回去重后的np.ndarray -
nunique():返回去重后的项目数量执行结果
空值的处理
空值会影响一些计算,如 NaN 与常数的运算结果均为 NaN。
Series / DataFrame 判断元素是否为空值,可用 isna() / isnull():返回对应的数据类型,原先元素所在位置以 True 和 False 代替:
有两种方式处理空值:
- dropna():去除空值所在行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
-
fillna(n):空值填充为n
练习
- 对于一个
DataFrame(记为df),如何查看各列中空数据的比例? - 对于前面的例子,如何查看身高和体重均未记录的数据?
参考答案
-
问题 1:
-
问题 2:
1 School Grade Name Gender Height Weight Transfer Test_Number Test_Date Time_Record 91 Tsinghua University Sophomore Yanfeng Han Male NaN NaN N 1 2019/9/7 0:04:45 102 Peking University Junior Chengli Zhao Male NaN NaN NaN 1 2019/10/13 0:03:55