XPath
约 1756 个字 80 行代码 18 张图片 预计阅读时间 7 分钟
Info
相关文章:XPath 选择器 | 阿啊阿吖丁
是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
HTML 可以视为一种不严格的 XML,所以也可以用 XPath 进行元素的查询。
准备
元素、属性与文本
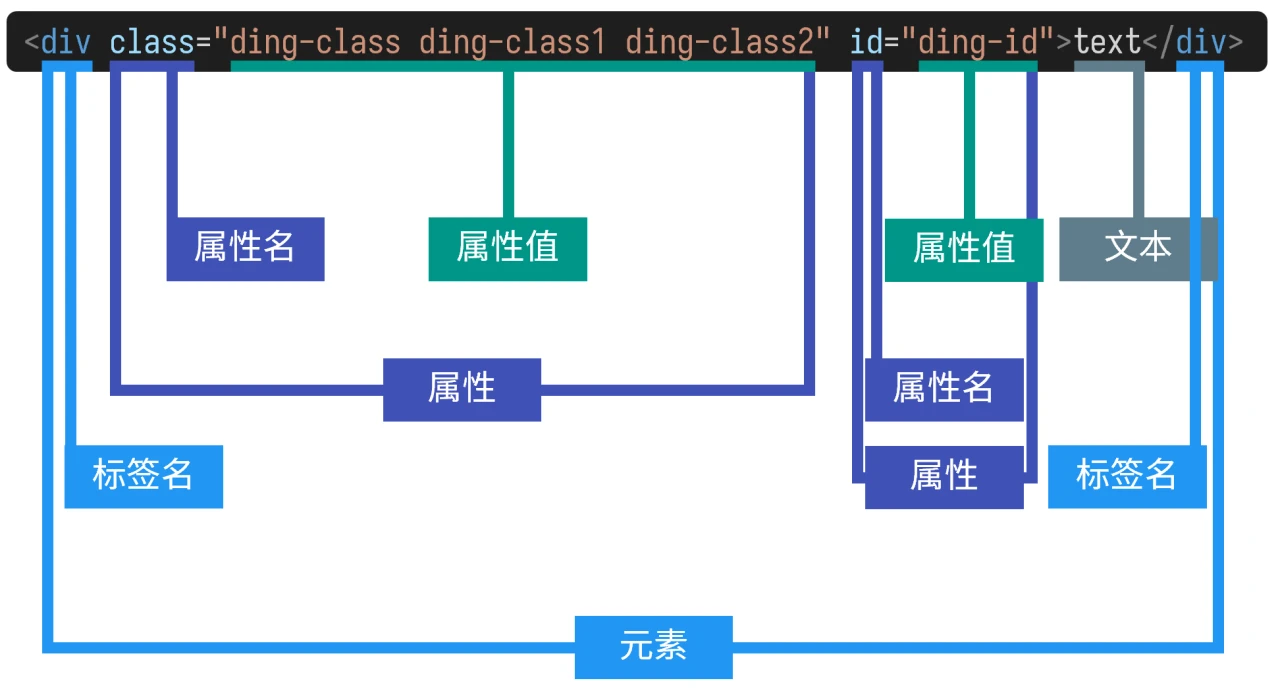
以下面的元素为例:
- 两边的
div是标签名 - 有两个属性:
class="ding-class ding-class1 ding-class2"- 属性名为
class - 属性值为
ding-class ding-class1 ding-class2
- 属性名为
id="ding-id"- 属性名为
id - 属性值为
ding-id
- 属性名为
- 夹在标签中间的
text是文本
元素间的关系
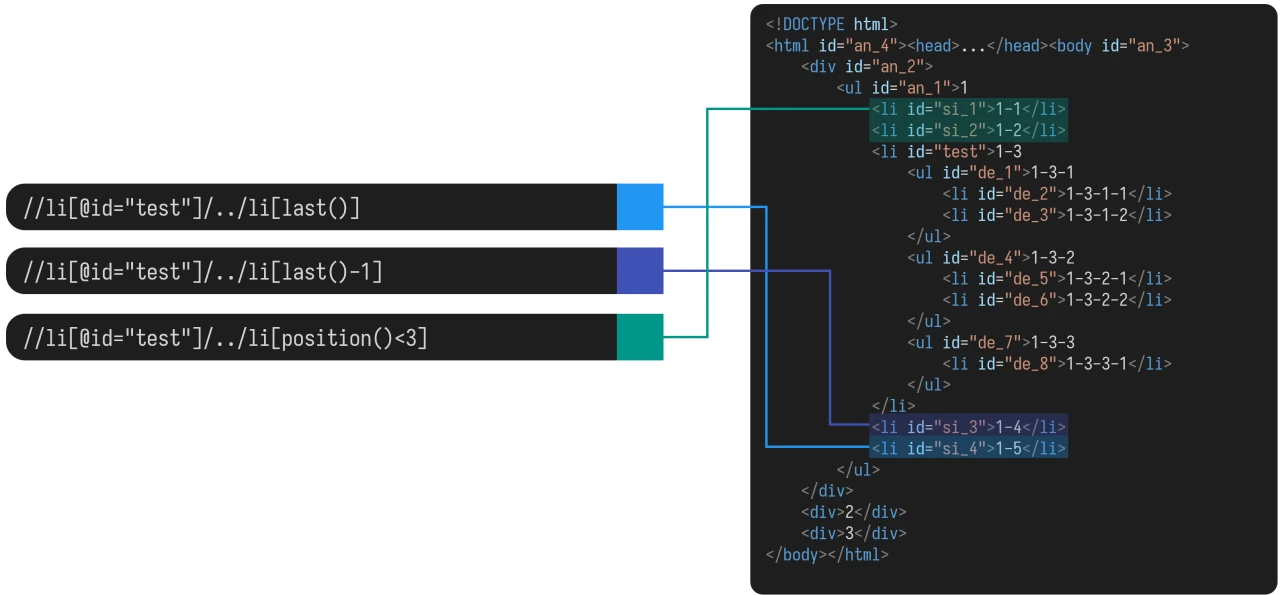
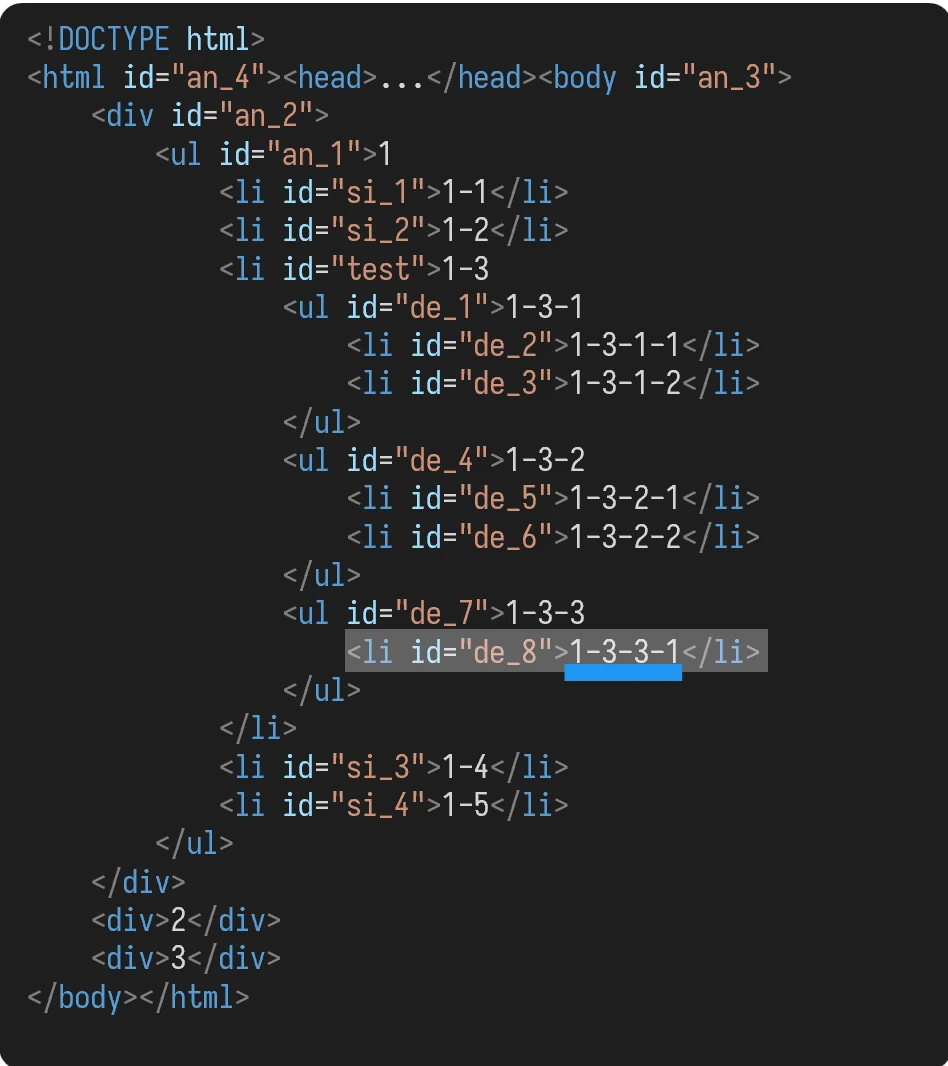
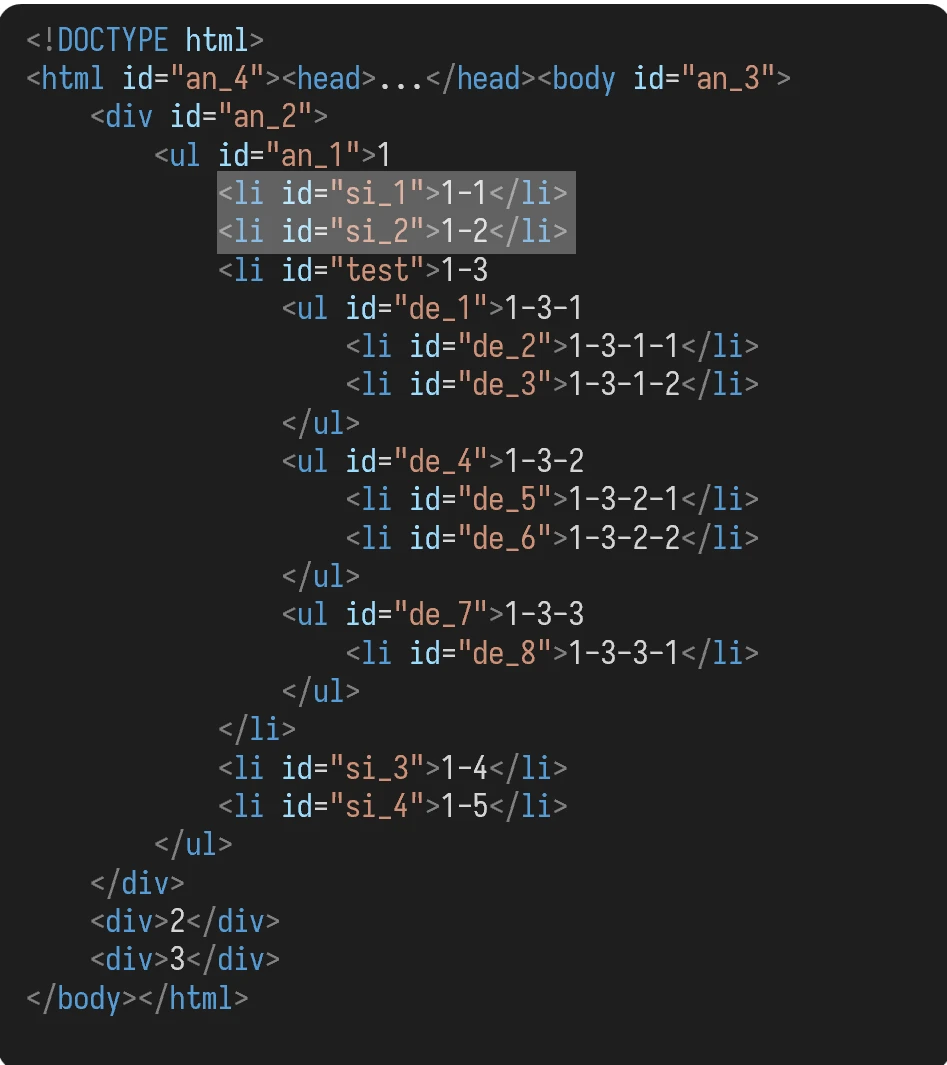
对于 id 为 test 的 li 元素而言:

它的父元素为 id 为 an_1 的 ul 元素;
它的先辈元素,除了父元素外,还有:
id为an_2的div元素id为an_3的body元素id为an_4的html元素

它的子元素有:
id为de_1的ul元素id为de_4的ul元素id为de_7的ul元素
它的后代元素,除了子元素外,还有:
id为de_2的li元素id为de_3的li元素id为de_5的li元素id为de_6的li元素id为de_8的li元素
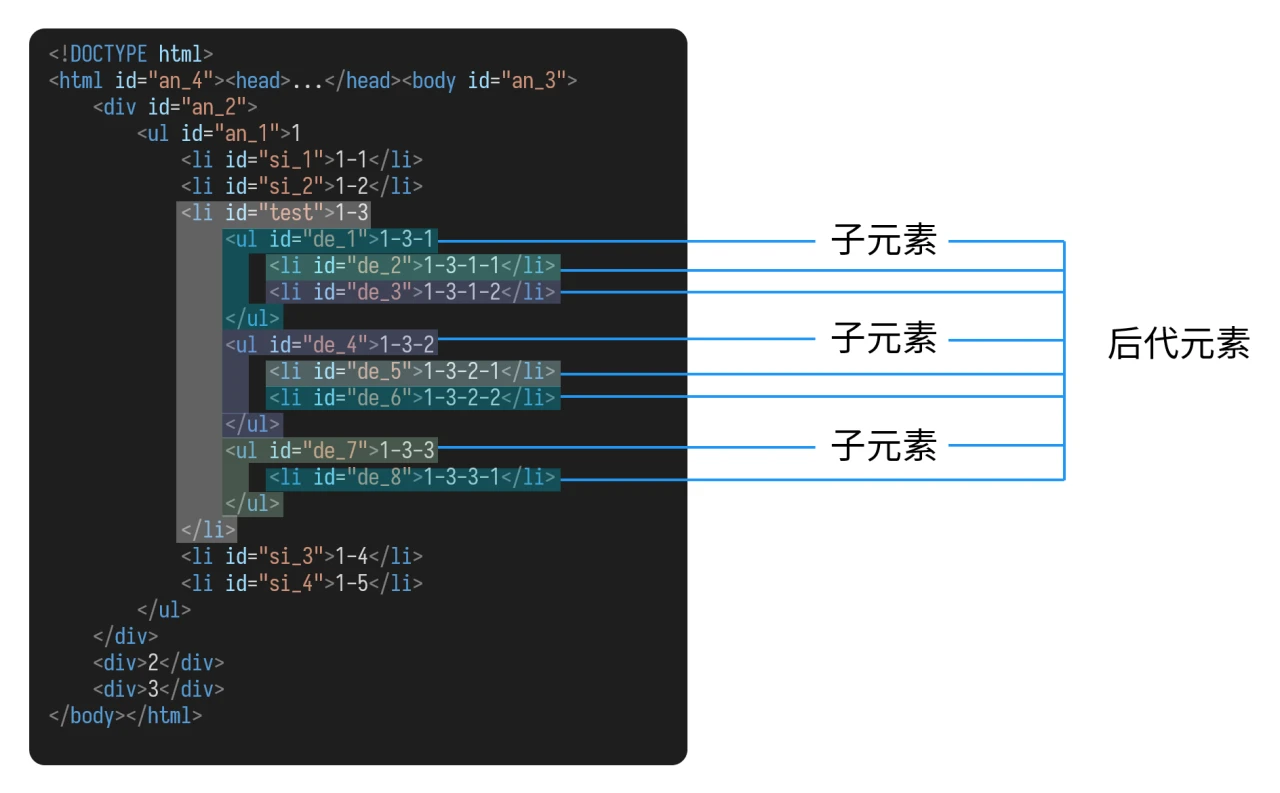
它的同胞元素中,
- 在它之前的同胞元素有:
id为si_1的li元素id为si_2的li元素
- 在它之后的同胞元素有:
id为si_3的li元素id为si_4的li元素

基本选取元素方式
绝对路径与相对路径
/ 开头为绝对路径,相对于整个 HTML 代码而言。否则为相对路径,只能在特定情况下使用。
标签、属性、下标与参数
标签直接写标签名即可。
表示任意标签用 *。
在标签后加上方括号 [],方括号内写这个元素的属性。
在属性中写上数字,表示选取第几个元素(下标从 1 开始)。
在参数名前加上 @,写在属性里,表示选取具有该参数的元素。@参数名=值 表示选取参数为某个值的元素。
文本值用什么包裹
文本值用单引号、双引号包裹都可以,只要统一就行,看个人习惯。
如果你要将其应用于编程,最好用你包裹字符串用的引号不一样的引号,免去转义的麻烦。
子元素、后代元素
子元素:元素/子元素;
后代元素:元素//后代元素。
以 // 开头可以简略 /html/body/...。
上例中选取的都是这个元素:
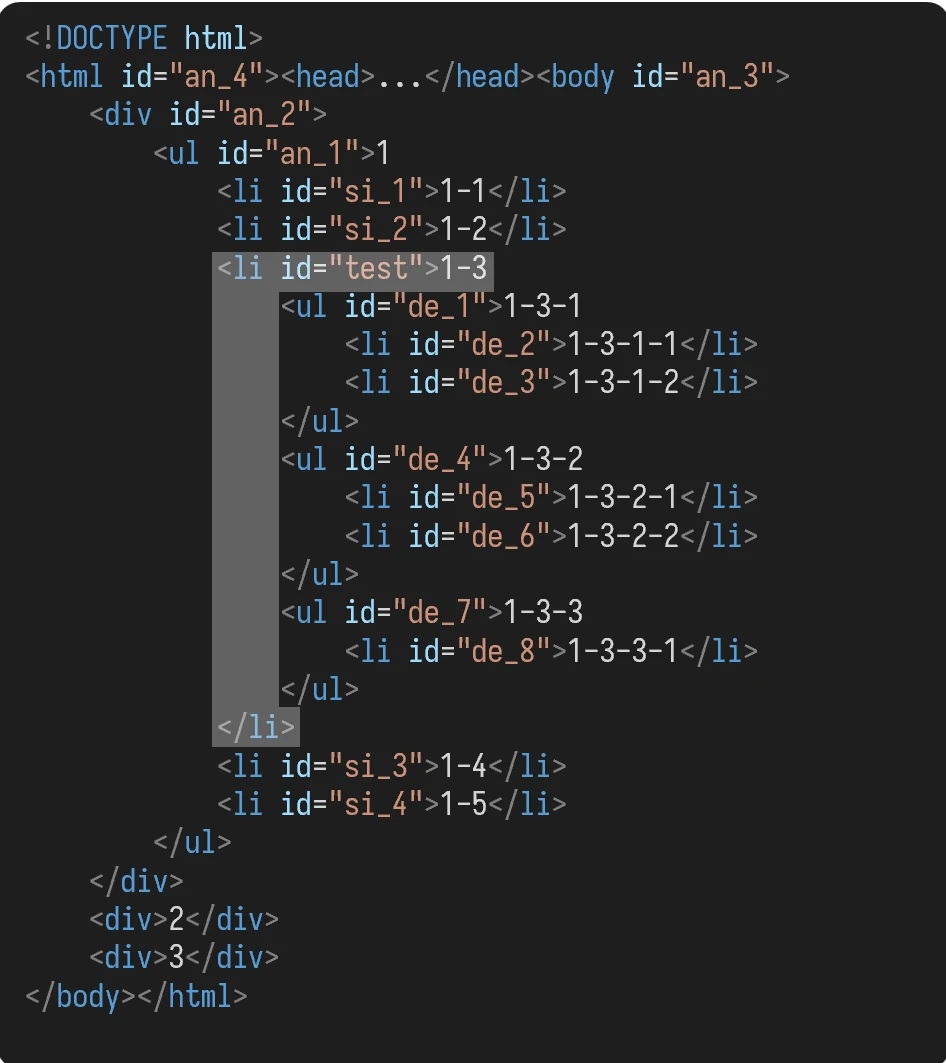
父元素
..
选取的元素:
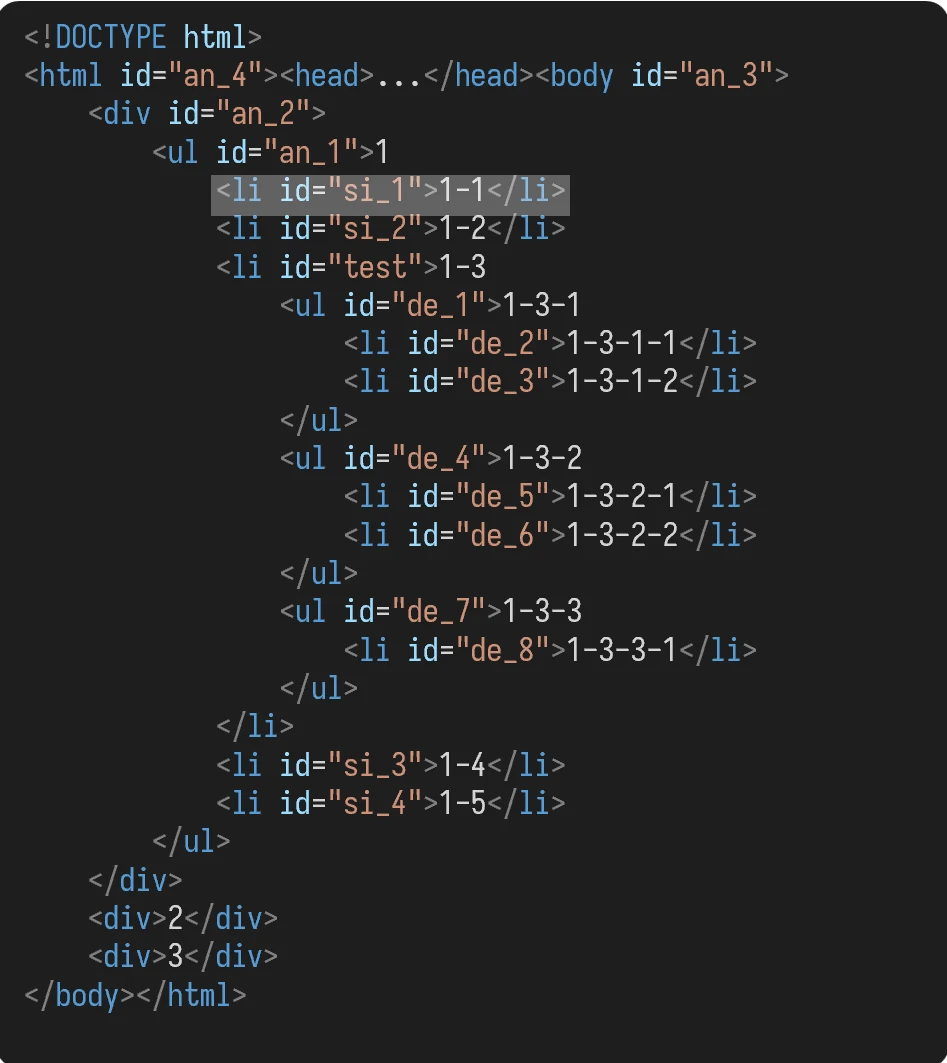
XPath 和文件路径的表达方式很像——所以有时候我们就叫“XPath 路径”。
. 表示自身。
运算与常用函数
基本运算
- 加减乘除:
a+ba-ba*ba div b - 取余:
a mod b - 比较:
a=ba!=ba<ba>ba<=ba>=b - 逻辑:
a and ba or bnot(a)
选取的元素为:
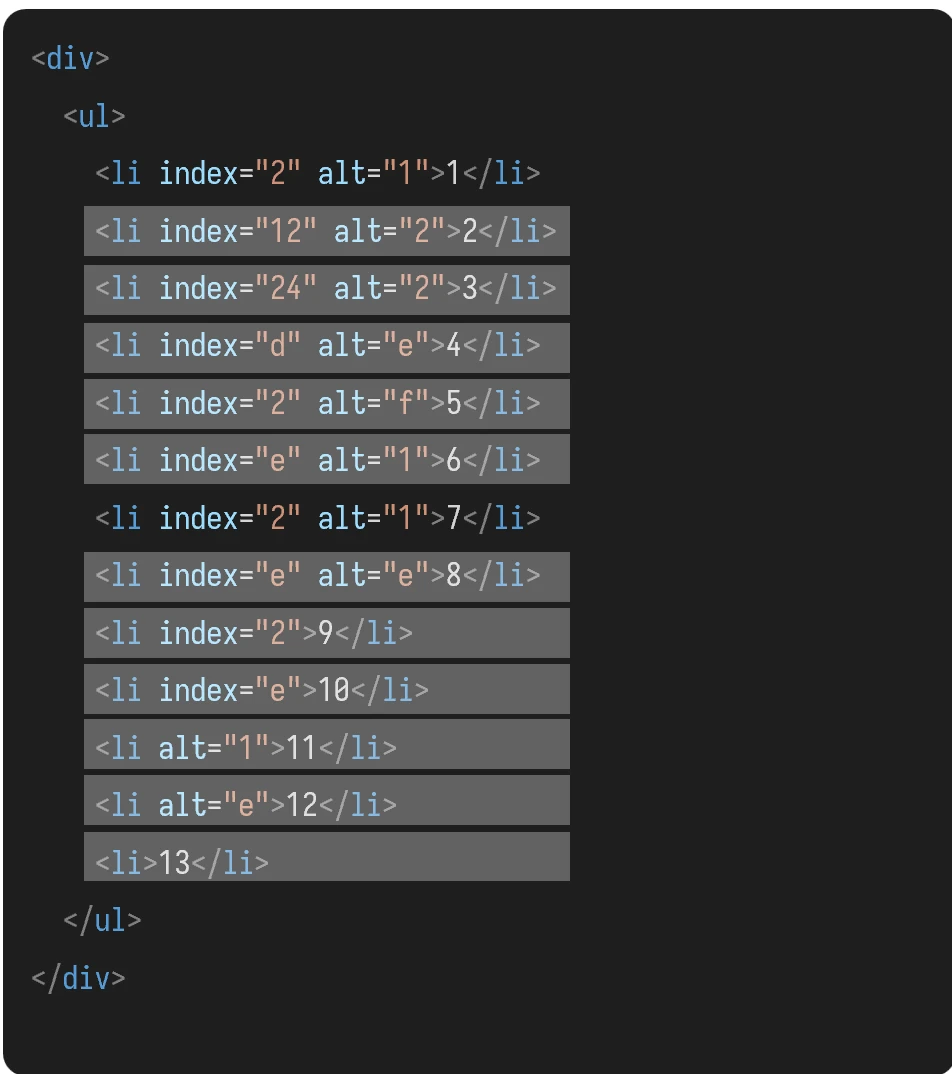
选取第几个元素
- 最后一个元素:
last() - 元素序号:
position()
它们选取的元素:
选取多个路径
使用 | 来连接多个路径
选取的元素为:

文字
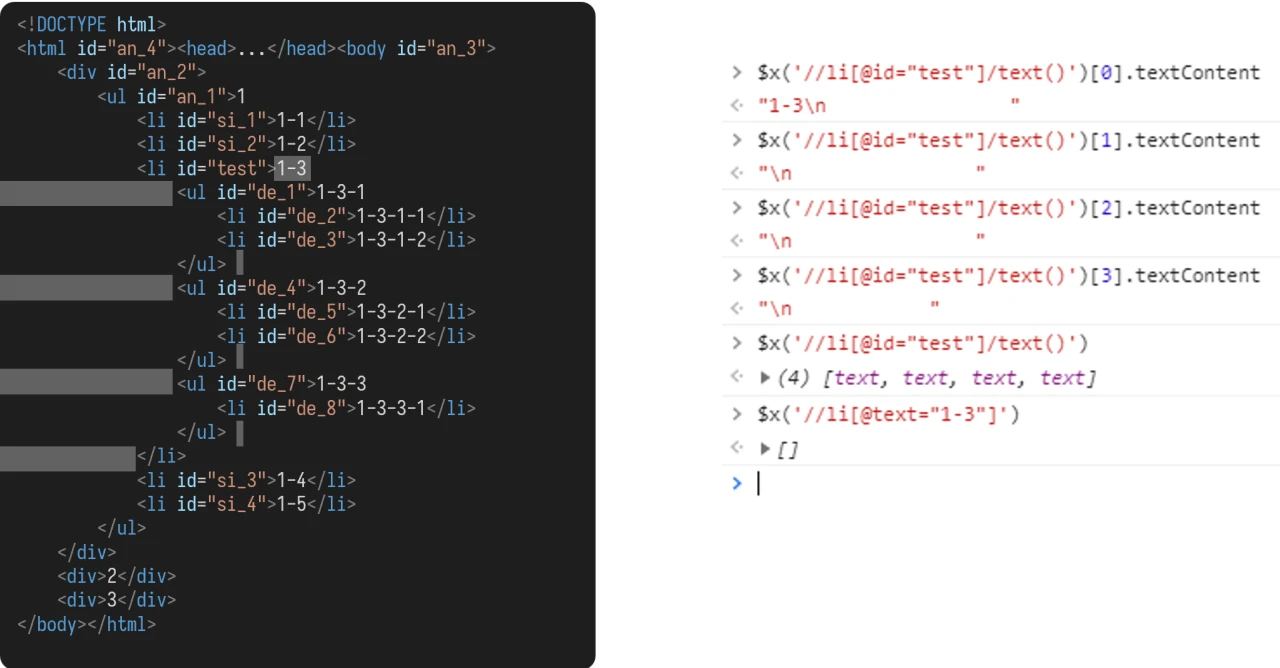
使用 text() 来表示文字。在 Web 自动化测试时,较常用于定义属性。
选取的元素为:
该函数取的文本不包括后代元素的文本,且如果有换行、空格和缩进,也会算进去。
如果换行和缩进之间被其他元素隔开,也会被分隔为两个部分。
包含
contains(a, b) 函数表示在 a 中包含 b。
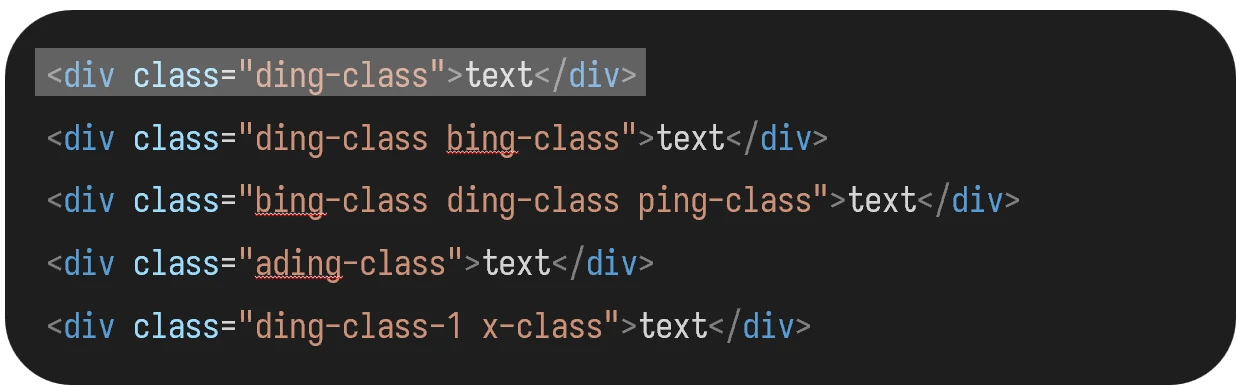
现在需要选取 class 属性带有 ding-class 的 div 元素:
这种方法是错误的,只会选取严格等于的选项:
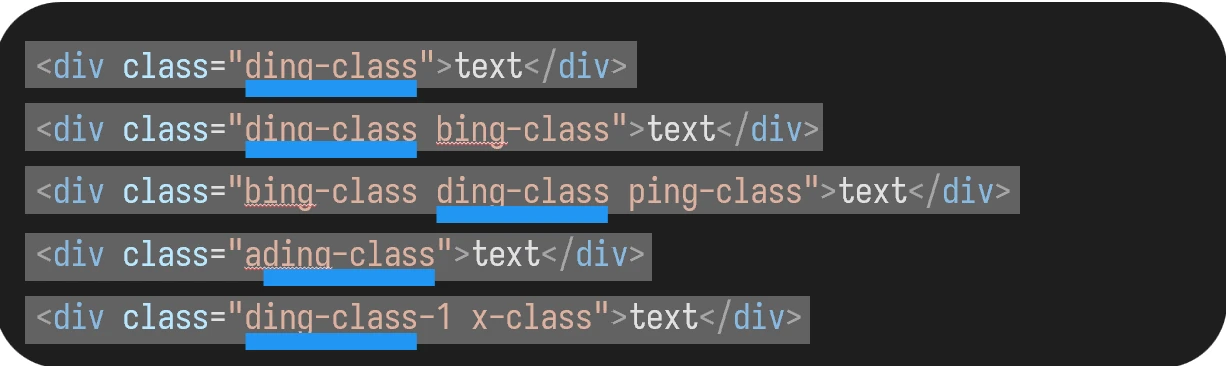
换用包含:
仍然错误,会选取不为 ding-class,但文本中有该字符串的 class:
连接
concat(a, b, ...) 函数表示连接 a、b...
使用该函数,结合上面的包含函数,可以精准选取 class 参数:
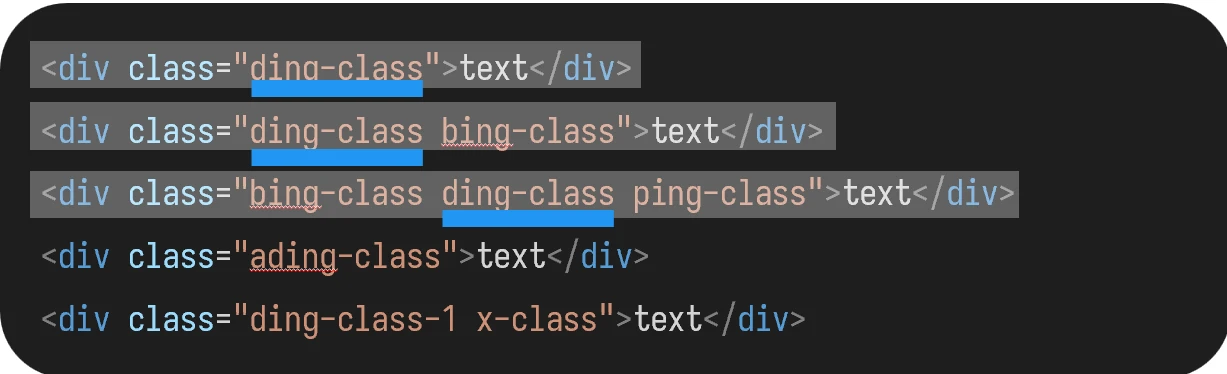
开头
starts-with(a, b) 函数表示 a 以 b 开头。
轴
用法
表示之前的元素的轴中,符合条件或下标的标签。
Web 自动化测试中常用的轴如下:
| 轴 | 含义 | 相当于 |
|---|---|---|
parent |
父元素 | .. |
ancestor |
先辈元素 | |
ancestor-or-self |
先辈元素与自身 | |
child |
子元素 | |
descendant |
后辈元素 | // |
descendant-or-self |
后辈元素与自身 | |
preceding |
之前的元素 | |
following |
之后的元素 | |
preceding-sibling |
之前的同胞元素 | |
following-sibling |
之后的同胞元素 |
例:
选取的元素:
轴与下标
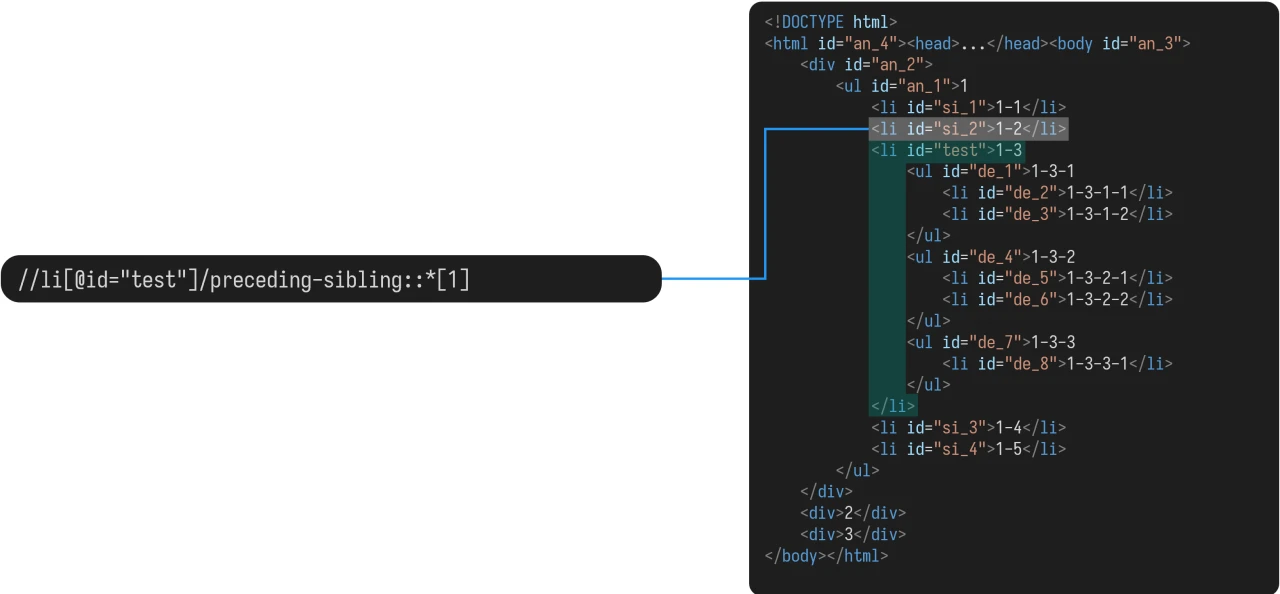
如果涉及到下标,根据该元素的位置,从近到远排序,而不是按照代码中的顺序排序。
例:
选取的元素:
书写选择器文本的诀窍
善用工具
浏览器的开发人员工具能够轻松调试选择器文本。
仔细观察层级结构和关系。
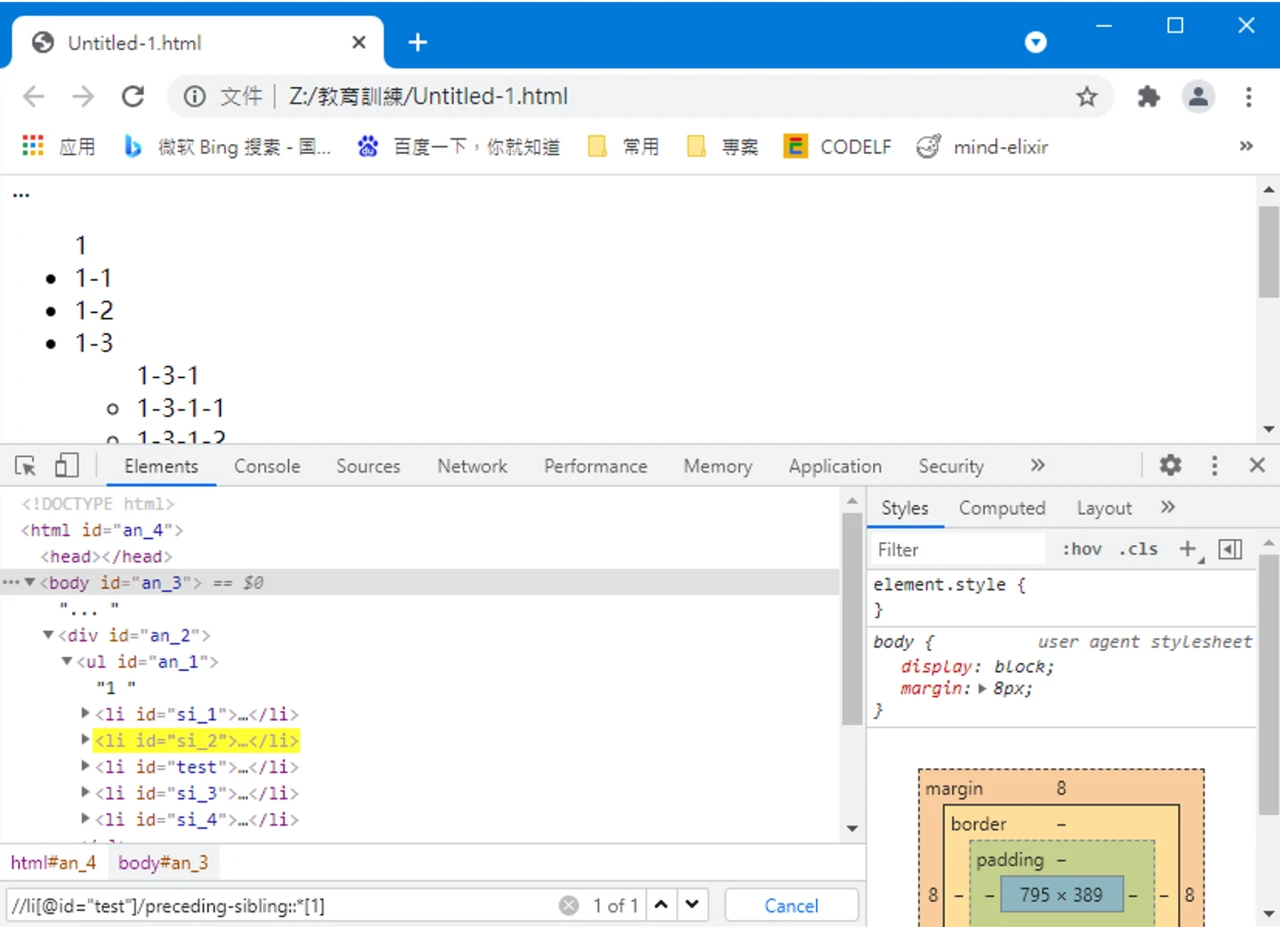
Chrome 和 Firefox 下均可以在控制台通过 $x() 函数来调试 XPath 语句:
另外,Chrome 下可以在元素标签页中使用搜索功能,直接输入 XPath 语句,即可查找对应的元素。
避免使用自动生成、层级过多、多处使用下标的嵌套
由于 Web 框架可能会增加添加层级和元素,这样的查询语句很容易查询不到想要的元素。
建议使用一些标志性的特征来定位。
如:
语法汇总
节点
本节点
也可以不写斜杠及之前的内容。
以此开头(或开头直接是节点)的以相对位置看待。
根节点
以此开头的以绝对位置看待。
父节点
子节点
选取直接在 a 下的 b 节点:
后代节点
选取 a 下的 b 节点,不管是直接在 a 下的,还是间接的:
从根节点下选取 a 节点,不管是直接在根节点下的,还是间接的:
兄弟节点
选取 a 元素之后的兄弟 b 元素。a 与 b 同级,非亲子关系:
选取 a 元素之前的兄弟 b 元素。
preceding-sibling 中,若结果有多个,在指定下标的时候,从离锚元素最近的元素开始,从 1 算起。如:
指 a 元素向前数,第二个兄弟 b 元素。
序数(第几个节点)
XPath 中以 1 为开始。
选取 parent 下的第 n 个 child 元素:
选取 parent 下的最后一个 child 元素:
选取 parent 下的倒数第二个 child 元素:
选取 parent 下的前两个 child 元素:
若涉及到锚元素,则下标从距离锚元素最近的目标元素开始数起,到最远处,不一定是从上到下。
选取若干个路径
选取 a 节点下的 b 节点,和 c 节点下的 d 节点:
属性
基本格式
选取 attr 属性为 value 的 node 节点:
节点内文本
选取 node 节点的所有文本:
选取文本内容为 value 的 node 节点:
运算
包含
选取在 a 中包含 b 的 node 节点:
选取文本内容中包含 b 的 node 节点:
选取 class 属性包含 b 这个字的 node 节点:
选取 class 属性包含 b 这个 class 的 node 节点: